jennyh :
Fact is, you wont get a 100% fair/tinfoil hat free benchmark unless you actually write one yourself.
Using Folding@home as an example is pretty flawed. It's still a piece of code, coded on a certain system. Nvidia own ATI in folding@home don't they? How come #5 in the supercomputer list uses 4870's and there isn't an nvidia to be seen then?
It's doing the same kind of work after all.
Would you like to know why nVIDIA trounces ATi in terms of F@H performance?
If you want to ward off a bunch of nVIDIA fanbois then the best thing is to look into why F@Hs GPU2 client works better on nVIDIA hardware. I did just that.
For me it started as a general question. Why is it that the RV770, offering nearly twice the computational power of the GT200, being left in the dust when it came to F@H. Looking at the pure theoretical numbers one would have to conclude that something was missing from the equation. For GT200 (GTX 280) we often heard computational quotes ranging from ~622GFLOPs to 933GFLOPs (something in that range). When you actually look at the architecture and notice that one of the MULs is non-functional (it only shows up in theoretical numbers) then you conclude that GT200 can only output 622GFLOPs of Single Precision computational performance. Now this could seem like a big number, that is until you have a look at RV770s theoretical peak of 1.2TFLOP/s.
So why is is that a 622GFLOP/s card bests a 1.2TFLOP/s card under F@Hs GPU2 client? That was the question I posed myself. Anyways I found the answers.
It all started with a scientific paper I read written by the F@H programmers over at Stanford University which you can view here:
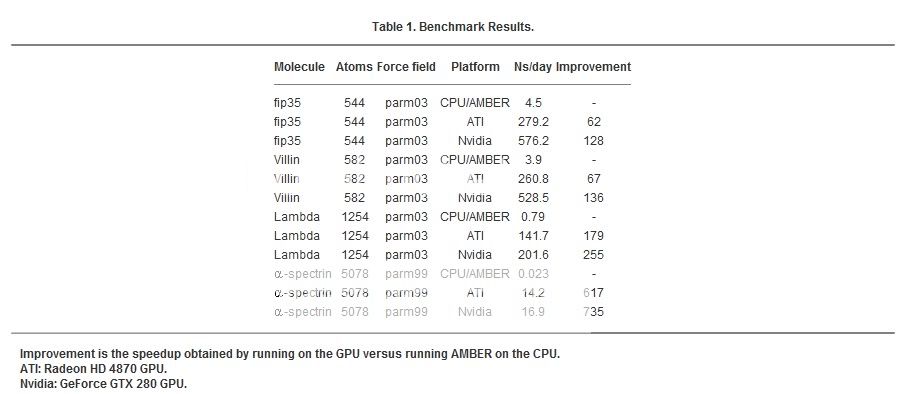
These are two screen shots of that particular scientific paper. What you will notice is that RV770 is often doing twice as many FLOPs for the same results (in other words RV770 is doing twice the work).
I was scratching my head wondering why RV770 would need to do twice the amount of work that GT200 does and then it hit me... protected memory access.
I remembered reading that nVIDIAs CUDA implementation allowed a GPU the ability to run threads in protected system memory (RAM) and use this memory to save intermediary results (like the memory function on a calculator). What this allowed GT200 to do was, upon error, go back to the last results before the error and continue from there. With RV770, the whole calculation needed to be flushed and started from scratch.
I literally came to that hypothesis on my own over at x c p u s (anyone who posts or frequents there can attest to that). I had frequent battles with a few nVIDIA fanbois and received quite a bit of flack over my hypothesis.
That being said I still did no know the rest of the equation.. that is until Vijay S. Pande filled in the blanks. He first mentioned something peculiar on his blog as you can read here:
http://folding.typepad.com/news/2009/09/update-on-new-fah-cores-and-clients.html
3) GPU3: Next generation GPU core, based on OpenMM. We have been making major advances in GPU simulation, with the key advances going into OpenMM, our open library for molecular simulation. OpenMM started with our GPU2 code as a base, but has really flourished since then. Thus, we have rewritten our GPU core to use OpenMM and we have been testing that recently as well. It is designed to be completely backward compatible, but should make simulations much more stable on the GPU as well as add new science features. A key next step for OpenMM is OpenCL support, which should allow much more efficient use of new ATI GPUs and beyond.
This revived my curiosity and it is at this point that I figured it all out here:
http://www3.interscience.wiley.com/journal/121677402/abstract
It is written by the F@H programmers.
Just as I suspected (my hypothesis was proven correct). This is why nVIDIA folds quicker than ATi. The ability to hold a sufficient number of intermediate values. Because if you get an error, ATi flushes out everything where as nVIDIA can pick up where it left off. Also, something I did not know was that nVIDIAs use of scattering allows them to effectively only need 1/2 the amount of calculations to reach a result. Both these explain why AMD boards are generating over twice the FLOPs (RV770 vs. GT200) yet not getting more work done.
Since both RV770 and RV870 support Scattering, Thread Synchronization and in the case of RV870 have a access to high speed cache (and can run threads in protected memory) we can expect a lot of performance from GPU3 (which makes use of OpenCL and OpenMM thus requiring the usage of these features).
This is all straight from Stanford (out of the horses mouth) not mine.
GPU2 works better on nVIDIA hardware due to a lacking feature in the ATi GPU2 F@H client (which RV670 did not support but which RV770 and newer do support and that is Scattering and Thread Synchronization). Add to that the fact that RV870 can now also run threads in protected memory and you've got a HUGE performance boost awaiting ATi users with the GPU3 client.
So the reason why F@H works better on nVIDIA than it does on ATi has got nothing to do with computational performance (for which ATi utterly trounce nVIDIA under most workloads) but rather due to small tiny features which were omitted from the ATi GPU2 client due to time constraints coupled with a missing feature now rectified with RV870 and newer.
")
PS: I just wanted to add this image to showcase how widely R600/RV670/RV770/RV870 (ATi's Super Scalar Architecture) performance varies based on various mathematical workloads: