- Feb 5, 2020
- 192
- 14
- 5,245








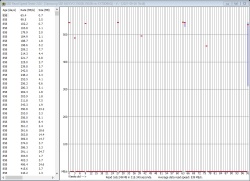
The Remaining Life (RL) of my Crucial MX500 ssd has been decreasing rapidly, even though the pc doesn't write much to it. Below is the log I began keeping after I noticed RL reached 95% after about 6 months of use.
Assuming RL truly depends on bytes written, the decrease in RL is accelerating and something is very wrong. The latest decrease in RL, from 94% to 93%, occurred after writing only 138 GB in 20 days.
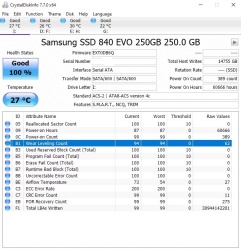
(Note 1: After RL reached 95%, I took some steps to reduce "unnecessary" writes to the ssd by moving some frequently written files to a hard drive, for example the Firefox profile folder. That's why only 528 GB have been written to the ssd since Dec 23rd, even though the pc is set to Never Sleep and is always powered on. Note 2: After the pc and ssd were about 2 months old, around September, I changed the pc's power profile so it would Never Sleep. Note 3: The ssd still has a lot of free space; only 111 GB of its 500 GB capacity is occupied. Note 4: Three different software utilities agree on the numbers: Crucial's Storage Executive, HWiNFO64, and CrystalDiskInfo. Note 5: Storage Executive also shows that Total Bytes Written isn't much greater than Total Host Writes, implying write amplification hasn't been a significant factor.)
My understanding is that Remaining Life is supposed to depend on bytes written, but it looks more like the drive reports a value that depends mainly on its powered-on hours. Can someone explain what's happening? Am I misinterpreting the meaning of Remaining Life? Isn't it essentially a synonym for endurance?
�
Assuming RL truly depends on bytes written, the decrease in RL is accelerating and something is very wrong. The latest decrease in RL, from 94% to 93%, occurred after writing only 138 GB in 20 days.
(Note 1: After RL reached 95%, I took some steps to reduce "unnecessary" writes to the ssd by moving some frequently written files to a hard drive, for example the Firefox profile folder. That's why only 528 GB have been written to the ssd since Dec 23rd, even though the pc is set to Never Sleep and is always powered on. Note 2: After the pc and ssd were about 2 months old, around September, I changed the pc's power profile so it would Never Sleep. Note 3: The ssd still has a lot of free space; only 111 GB of its 500 GB capacity is occupied. Note 4: Three different software utilities agree on the numbers: Crucial's Storage Executive, HWiNFO64, and CrystalDiskInfo. Note 5: Storage Executive also shows that Total Bytes Written isn't much greater than Total Host Writes, implying write amplification hasn't been a significant factor.)
My understanding is that Remaining Life is supposed to depend on bytes written, but it looks more like the drive reports a value that depends mainly on its powered-on hours. Can someone explain what's happening? Am I misinterpreting the meaning of Remaining Life? Isn't it essentially a synonym for endurance?
�
Crucial MX500 500GB SSD in desktop pc since summer 2019 | |||
Date | Remaining Life | Total Host Writes (GB) | Host Writes (GB) Since Previous Drop |
12/23/2019 | 95% | 5,782 | |
01/15/2020 | 94% | 6,172 | 390 |
02/04/2020 | 93% | 6,310 | 138 |