- Nov 21, 2018
- 26,985
- 1,246
- 44,560
























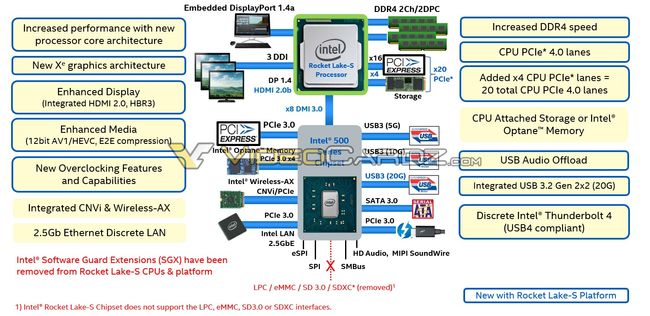
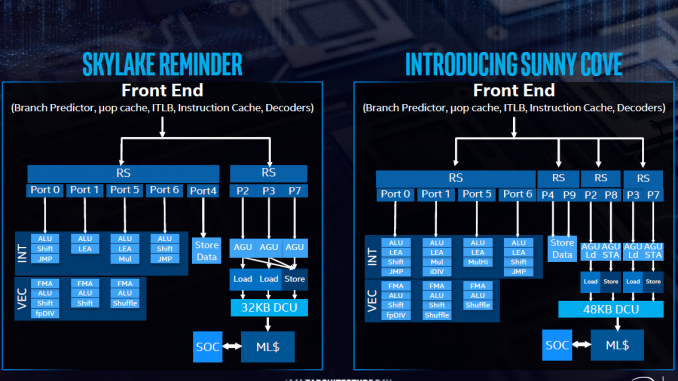
Intel's last 14nm desktop CPU, Rocket Lake-S, will have big changes according to a new leak. It will feature a new core architecture, Xe graphics, PCIe 4.0 support, twice the DMI 3.0 bandwidth and Thunderbolt 4.
Intel 14nm Rocket Lake-S Leaked: New Core Architecture, Xe Graphics, PCIe 4.0 : Read more
Intel 14nm Rocket Lake-S Leaked: New Core Architecture, Xe Graphics, PCIe 4.0 : Read more























































 Twitter
Twitter