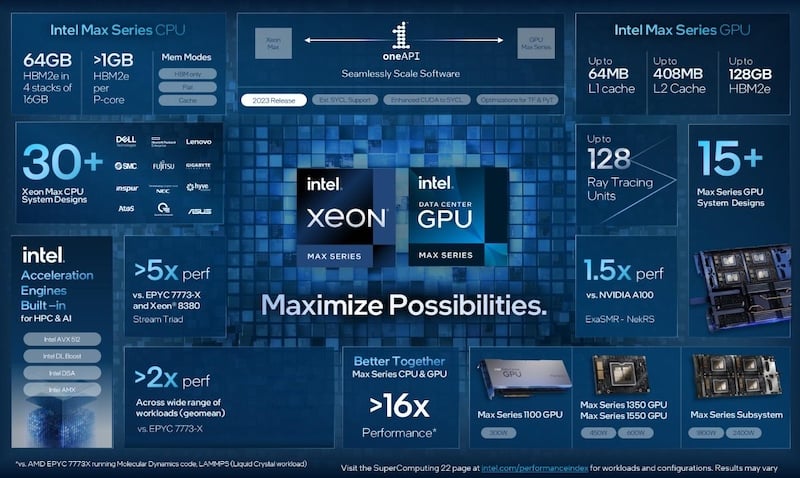
AI Workloads
First off, there's simply no way a CPU without a comparable matrix-multiply can compete with AMX. So, let's get that out of the way, up front. Of course, for heavy AI workloads, I don't expect most people to be using a CPU as their main AI compute engine.
Note that they're not comparing against GPUs or other AI accelerators!
Credit to
@PaulAlcorn , as I had noted the same things but he was already ahead of me:
"We also see a ~5.5X advantage in BertLarge natural language processing with BF16, but that is versus Genoa with FP32, so it isn't an apples-to-apples test. Intel notes that BF16 datatypes were not supported with AMD's ZenDNN (Zen Deep Neural Network) library with TensorFlow at the time of testing, which leads to a data type mismatch in the BertLarge test. The remainder of the benchmarks used the same data types for both the Intel and AMD systems, but the test notes at the end of the above image album show some core-count-per-instance variations between the two tested configs -- we've followed up with Intel for more detail [EDIT: Intel responded that they swept across the various ratios to find the sweet spot of performance for both types of chips]."
Further observations:
- Used Genoa with 2 DIMMs per channel (see end notes) - doesn't that incur a speed penalty? Also equipped Xeon with 2 DIMMs per channel. I wonder if the penalty is as much?
- Genoa had NPS=1 (NPS=4 typically yields better performance).
- Of course, they're using CPUs with the same core-count, when one of the main selling points of Genoa is that it has more cores.
Regarding that last point:
"per-core software licensing fees being the company's rationale for why these remain comparable."
None of the software in their benchmarks has per-core licensing. I'm pretty sure it's all open source, even.
General Workloads
I don't have much to say here, except that AMD is clearly using higher core-counts in opposition to Intel's increased reliance on accelerators. So, it seems logical to use another factor, like price, to determine which CPUs to match up to each other.
Also, where specified, most tests used NPS=1, except for the FIO test, GROMACS, and LAMMPS.
Finally, some of the tests used RHEL or Rocky Linux, with a 4.18 kernel. You really have to wonder how many of the more recent optimizations got backported to these ancient kernels, for the respective CPUs.
HPC Workloads
In this category, it would be really nice to have AMD's 3D V-cache equipped CPUs, but I guess they still have yet to launch the Genoa version? Maybe AMD is planning to do that at the Tuesday event.
Again, I'm struck by how many of these benchmarks used an ancient 4.18 kernel. I would expect HPC users to be a lot more interested in running newer kernels, in order to extract the most performance from their massive hardware and energy expenditures. Not only that, but such old distros won't have the compiler optimizations needed to enable features like AVX-512 on Genoa. However, in some cases, they do seem to make a point of compiling with AVX2 on both CPUs.
I'm pleased to see NPS=4, on all cases except Stream. I guess they felt they had enough bandwidth to spare, that they could allow this.






















































 Twitter
Twitter