- Nov 21, 2018
- 26,767
- 1,239
- 44,560
























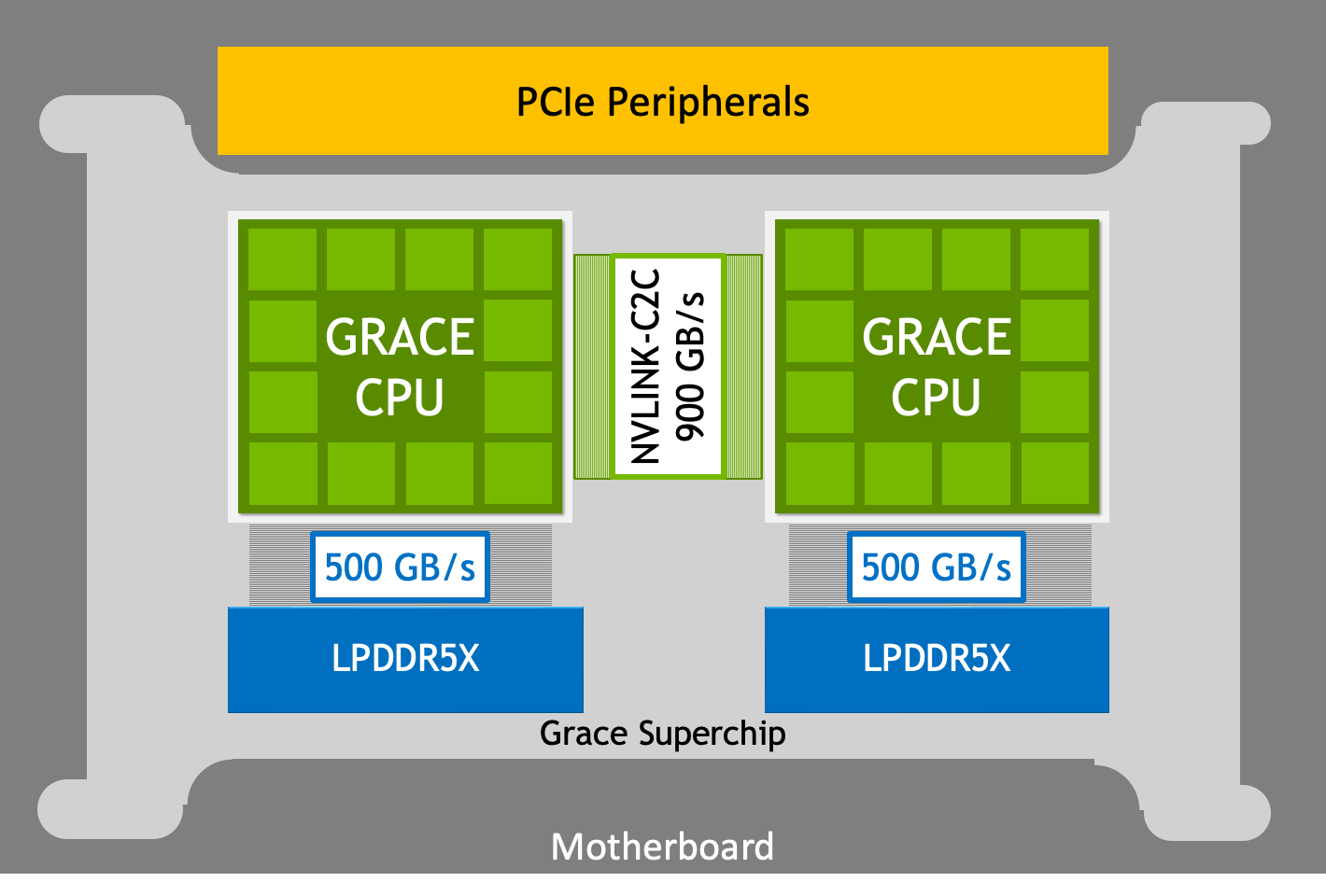
The 144-core Grace Superchip couldn't catch up to a 96-core dual-socket Sapphire Rapids server, but it may prove to be more efficient.
Nvidia Grace Superchip loses to Intel Sapphire Rapids in HPC performance benchmarks, but promises greater efficiency : Read more
Nvidia Grace Superchip loses to Intel Sapphire Rapids in HPC performance benchmarks, but promises greater efficiency : Read more









 Twitter
Twitter