- Nov 21, 2018
- 26,896
- 1,243
- 44,560
























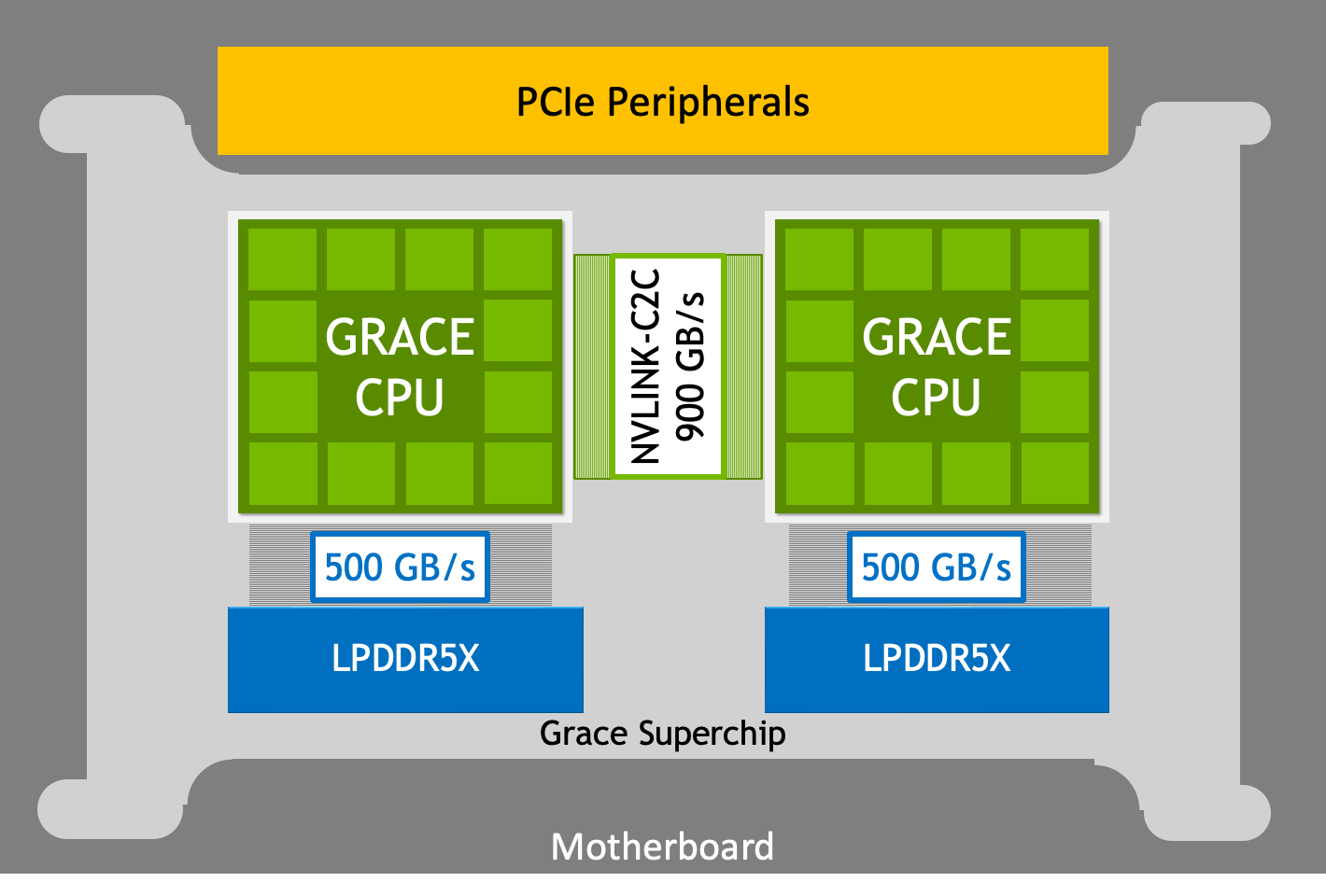
Nvidia announced that its Grace Hopper CPU+GPU Superchips are now in production, and also introduced the DGX GH200 supercomputer and MGX platforms that will use its new AI-optimized Ethernet Spectrum-X networking platform.
Nvidia Unveils DGX GH200 Supercomputer and MGX Systems, Grace Hopper Superchips in Production : Read more
Nvidia Unveils DGX GH200 Supercomputer and MGX Systems, Grace Hopper Superchips in Production : Read more









 Twitter
Twitter