Because most of your accesses would go to in-package DRAM stacks, which are potentially much faster.
According to this, CXL might add < 2x the latency of existing DIMMs, which isn't a bad tradeoff if most of your accesses stay in-package.
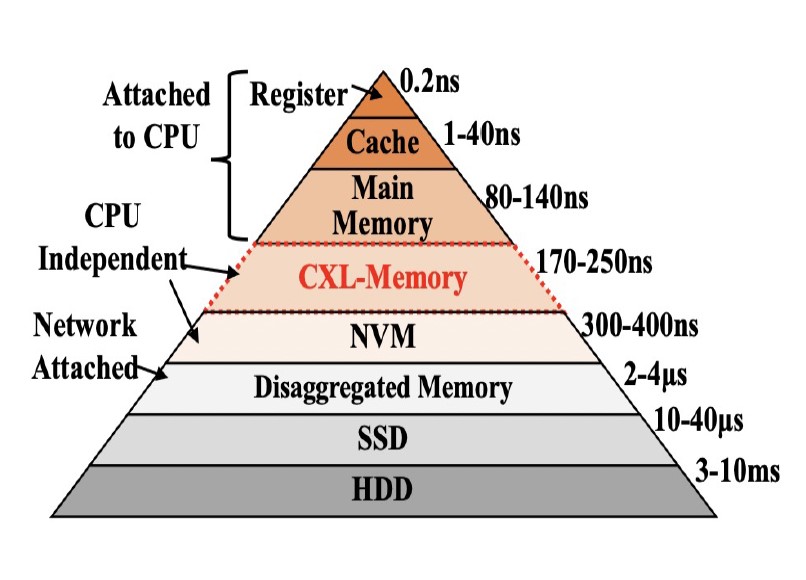
As I explained above, it's not the controller that makes Optane SSDs special. What will replace Optane SSDs, in the CXL-dominated world of tomorrow, is battery/NAND-backed DRAM. You'll get all the speed of DRAM, but with persistence. And if you don't need persistence, then you can simply use regular DRAM modules.
I didn't follow that product line, but my guess is that they primarily used the Optane memory as a fast write-buffer, whereas most drives use NAND in pseudo-SLC or pseudo-MLC mode. If you dig into write-oriented benchmarks, you'll probably see the benefit of this approach. I'm not saying it's worth the added cost, but to properly assess them, you must understand where they're trying to add value.

























































")
 Twitter
Twitter