is it really an IPC gap or an optimization issue? Ofcourse programmers tend to optimize their code according to the market sales. and Intel has been the market leader for nearly a decade, surpassing AMD sales with huge margin. I am not an expert but the cause of this IPC gap can be defined like "Hardware IPC+Software Efficiency". And if we take this into consideration, how much performance can be gained if the code is to be optimized for Ryzen? will it be still the same? or do we have some opportunity here?
Here's a rule of thumb: For non specialized software, assume zero optimization by the developer. We don't concern ourselves that much with architecture level improvements, unless there's a reason for it. We're more focused on higher order performance factors (algorithmic, etc).
Seriously, the days where we'd manually drop MMX and a few SSE opcodes into our source code is long gone. It's all compiler optimization now. And just from what I've seen in the industry, there's still a LOT of MSVC 2008, or even 2005 still floating around. So no fancy AVX opcodes for you.
CatMerc said: ↑ @The Stilt I have a question. Let's say I buy an AM4 motherboard and a Summit Ridge CPU now, and then later replace that Summit Ridge with a Pinnacle Ridge.
Does the chipset affect memory latency at all? I'd be completely satisfied with X370 I/O wise, but if waiting for X470 would mean getting lower memory latency I'd do it.
Basically I'm asking if pairing Pinnacle Ridge with X470 would give performance advantages over X370. No.
The chipset just provides additional IO to the CPU, similar to e.g. PCI-E to USB3 peripheral controller would.
The chipset isn't required for the CPU to function and on Crosshair VI Hero you can actually completely disable the external PCH.
CatMerc said: ↑ @The Stilt I have a question. Let's say I buy an AM4 motherboard and a Summit Ridge CPU now, and then later replace that Summit Ridge with a Pinnacle Ridge.
Does the chipset affect memory latency at all? I'd be completely satisfied with X370 I/O wise, but if waiting for X470 would mean getting lower memory latency I'd do it.
Basically I'm asking if pairing Pinnacle Ridge with X470 would give performance advantages over X370. No.
The chipset just provides additional IO to the CPU, similar to e.g. PCI-E to USB3 peripheral controller would.
The chipset isn't required for the CPU to function and on Crosshair VI Hero you can actually completely disable the external PCH.
What the Stilt claims is irrelevant to the comment was made in this thread. He talks about stock settings. My comment was about overclocking.
400-series mobos will reduce memory latency because "400 Series motherboards are designed to improve memory stability and overclocking" as AMD's James stated. The new mobos will be able to hit higher clocks than 300-series mobos. And latency is inversely proportional to the clocks.
AdoredTV is making some noise (an waves) as usual with this shocker...
Which also happens to be great journalism an fair play to him.
This will keep them all on their toes ! check it out.
AdoredTV is making some noise (an waves) as usual with this shocker...
Which also happens to be great journalism an fair play to him.
This will keep them all on their toes ! check it out.
A Flawed Perspective:
https://youtu.be/Uw0ZzA9wTFE
He puts a spotlight on what everyone has already known about PCPer. Good for him, we need more truth and integrity when it comes to real journalism.
AdoredTV is making some noise (an waves) as usual with this shocker...
Which also happens to be great journalism an fair play to him.
This will keep them all on their toes ! check it out.
A Flawed Perspective:
https://youtu.be/Uw0ZzA9wTFE
He puts a spotlight on what everyone has already known about PCPer. Good for him, we need more truth and integrity when it comes to real journalism.
is it really an IPC gap or an optimization issue? Ofcourse programmers tend to optimize their code according to the market sales. and Intel has been the market leader for nearly a decade, surpassing AMD sales with huge margin. I am not an expert but the cause of this IPC gap can be defined like "Hardware IPC+Software Efficiency". And if we take this into consideration, how much performance can be gained if the code is to be optimized for Ryzen? will it be still the same? or do we have some opportunity here?
Windows code is usually optimized for ancient CPUs, so it cannot use the newest features in modern Intel CPUs and that is why the average IPC gap with RyZen is lower ~15% in windows reviews.
Linux code is usually more optimized for modern CPUs. Moreover, The Stilt compiled the linux code for the latest architectures (including RyZen) and that is why the average IPC he measured increased to ~30%.
In Windows reviews you can find few benchmarks where the IPC gap is around ~30%. I gave some examples above (Audacity, Hitman, 7-zip, WinRAR, Adobe Lightroom). In Linux reviews you can find many benchmarks where the IPC is around 30% and you can benchmarks where the IPC gap is higher than 200%.
Those benchmarks are suspect because Ryzen typically outperforms Intel clock for clock in linpack due to the considerably better SMT implementation.
Additionally, I notice that you are only using benchmarks where AVX advantage is heavily leveraged to exacerbate your claims.
is it really an IPC gap or an optimization issue? Ofcourse programmers tend to optimize their code according to the market sales. and Intel has been the market leader for nearly a decade, surpassing AMD sales with huge margin. I am not an expert but the cause of this IPC gap can be defined like "Hardware IPC+Software Efficiency". And if we take this into consideration, how much performance can be gained if the code is to be optimized for Ryzen? will it be still the same? or do we have some opportunity here?
Windows code is usually optimized for ancient CPUs, so it cannot use the newest features in modern Intel CPUs and that is why the average IPC gap with RyZen is lower ~15% in windows reviews.
Linux code is usually more optimized for modern CPUs. Moreover, The Stilt compiled the linux code for the latest architectures (including RyZen) and that is why the average IPC he measured increased to ~30%.
In Windows reviews you can find few benchmarks where the IPC gap is around ~30%. I gave some examples above (Audacity, Hitman, 7-zip, WinRAR, Adobe Lightroom). In Linux reviews you can find many benchmarks where the IPC is around 30% and you can benchmarks where the IPC gap is higher than 200%.
Those benchmarks are suspect because Ryzen typically outperforms Intel clock for clock in linpack due to the considerably better SMT implementation.
Additionally, I notice that you are only using benchmarks where AVX advantage is heavily leveraged to exacerbate your claims.
There is no better SMT implementation. The Zen core extracts less ILP from code and thus leaves more execution units free for executing a second thread
The Stilt just proves what we know about the microarchitectures. Haswell and Kabylake are 16FLOP/core, whereas Zen is 8FLOP/core. So the performance gap is about the double and The Stilt measured 1.89 and 2.22. Note that Skylake-X and SP are 32FLOP/core and increase still more the performance gap with Zen.
I have given both AVX and non-AVX workloads. Moreover, there is nothing wrong on giving AVX workloads. Would us stop using the last versions of Handbrake and Blender because support AVX and put AMD CPUs in a worse position? Obviously, no.
OrangeKhrush said: ↑
Juan is going to be the most roasted man on the internet. He better get the KY ready.
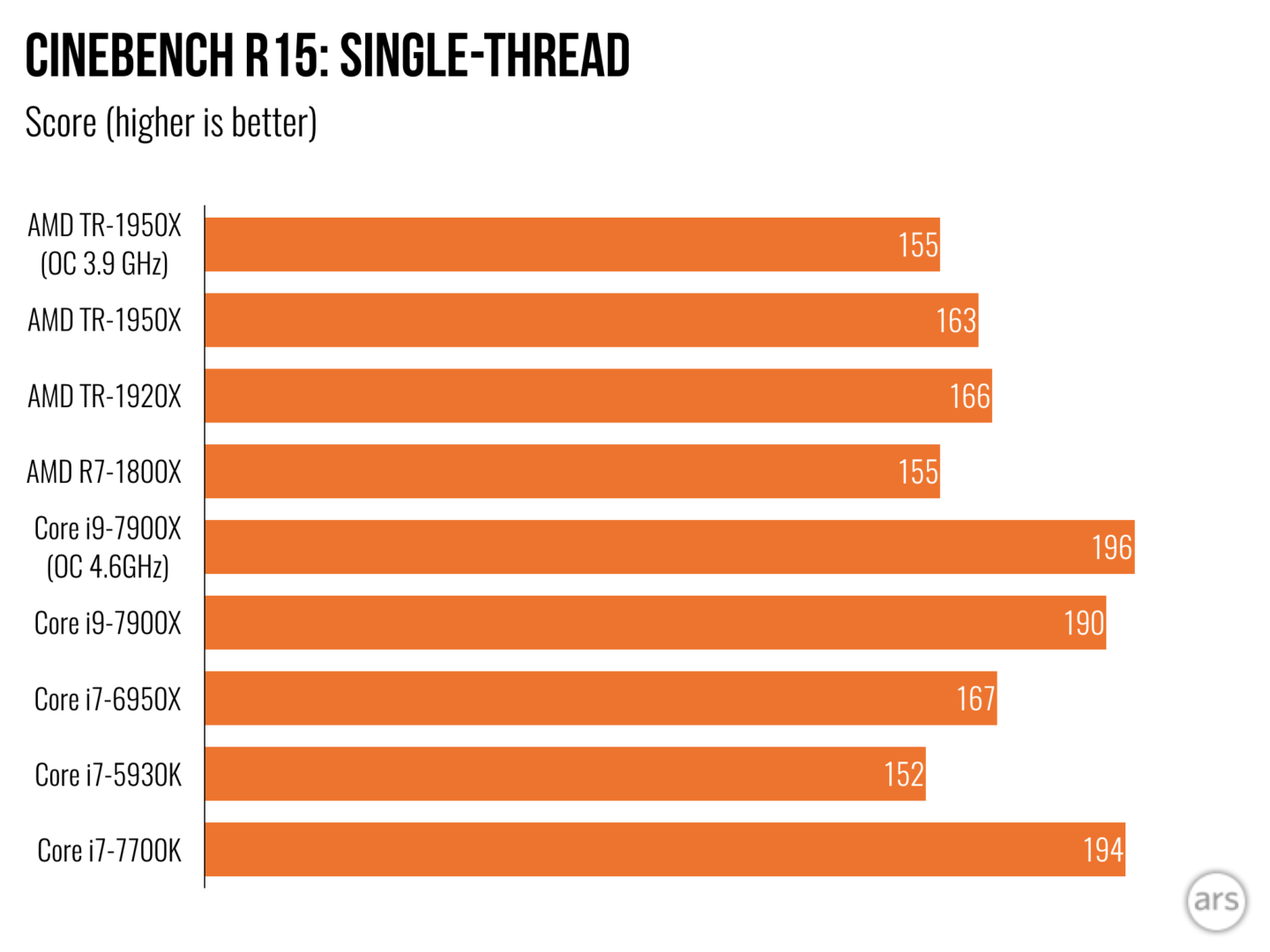
Anyways it looks like Ryzen is about 5% off Broadwell and 8% off Skylake clock for clock which is a really good effort.
What was Juan's IPC prediction ? SB level?
OrangeKhrush said: ↑
Juan is going to be the most roasted man on the internet. He better get the KY ready.
Anyways it looks like Ryzen is about 5% off Broadwell and 8% off Skylake clock for clock which is a really good effort.
What was Juan's IPC prediction ? SB level?
Juangra I see you mentioned all over Anandtech, but I can't look up your user name? Are you no longer a member there?
I am not on Anandtech. They know me from other places including here
Rogue Leader :
As a Moderator to help the discussion along I think I need to step in here and nip this in the bud
OrangeKhrush is a former member here who went by a different name, I would take any information from him with a grain of salt. I wouldn't waste any effort on information from him.
Thanks all
This history did start about one year before RyZen launch. OrangeKrush and his group of fanboys were wrong about virtually everything what they predicted about Zen. They predicted die smaller than 150mm², whereas I predicted 205mm², they predicted quad-channel for AM4 whereas I predicted dual-channel, they talked about 5GHz on air when I said them Ryzen would hit a wall about 4Ghz, they predicted 256bit FMAC units when I predicted 128bit, and so on. [1]. The list of their mistakes in interminable and it extends to other stuff like their failed predictions about Carrizo, Bristol, Ridge, Polaris, Vega, or even the new Sony console. For instance, they predicted Jaguar cores at 3.2GHz for the new PS4 console, whereas my reply was Sony would be lucky to get 2.3GHz. The response I received was "You talk how Sony would be lucky to reach less clocks with FinFET than the current 2.5GHz at 28nm. That is complete non sense". Finally the PS4 Pro has Jaguar cores clocked at 2.13GHz.
They lie about what I said in the hope that this will hide all their mistakes. I never said that Zen IPC was Nehalem, for instance, but they said 5% higher than Kabylake; I didn't say Athlon XP clocks, but they said 4.5GHz and even 5GHz. OrangeKrush is so obsessed with me that in one occasion he took a photo mine from Internet, edited it and used as his avatar, posting on Anandtech like if he was me (something about that episode is mentioned in your link).
Even when he gives me some credit (which only happened once so far as I know) he is plain wrong! Check this comment from him. First, the correct technical term is speed-demon, not 'speedster' as he writes. Moreover, he is wrong about my argument. I said that Zen would hit a ~4GHz wall by using 14LPP node, not because the microarchitecture is brainiac and limited to those clocks. Zen ported to 14HP could get higher clocks without problem. The current limit is in the 14LPP process node not in the Zen microarchitecture.
Apart from lying about what I said, their other tactic to hide their mistakes in predictions/leaks consists on refuting data and inventing crazy theories. OrangeKrush invented then the nonsensical theory that the first RyZen models AMD was selling the past year weren't real Ryzen, but rebranded engineering samples, with real silicon coming latter in the second half of 2017. He also invented a crazy history about the 1700X requiring a B350 as minimum, and thus, benchmarks running on A320 mobos not showing the true potential of Ryzen because turbo is disabled on those boards. LOL.
[1] Some failed predictions from that people regarding Zen: 3x256bit FMAC units per core, 4.0GHz or higher base clocks and turbo around 4.5GHz for the 8C 95W model, big core (~10mm²), overclocks to 5GHz on air stable 24x7, superenthusiast 5GHz 8-core stock model, 60% more efficient than Broadwell-E on Handbrake, quad-channel AM4 socket with native support (not oc) above 3000MHz DRAM, 10-wide issue Zen core, IPC 5% above Kabylake (non-AVX), CMT instead SMT, HBM2 as L4 cache on Raven Ridge APUs and EPYC server, $350 for the top RyZen model, usage of TSMC 16nm node, DDR3 support optional, launch in 2016, special 16-core dies for servers,...
There is no better SMT implementation. The Zen core extracts less ILP from code and thus leaves more execution units free for executing a second thread
The Stilt just proves what we know about the microarchitectures. Haswell and Kabylake are 16FLOP/core, whereas Zen is 8FLOP/core. So the performance gap is about the double and The Stilt measured 1.89 and 2.22. Note that Skylake-X and SP are 32FLOP/core and increase still more the performance gap with Zen.
I have given both AVX and non-AVX workloads. Moreover, there is nothing wrong on giving AVX workloads. Would us stop using the last versions of Handbrake and Blender because support AVX and put AMD CPUs in a worse position? Obviously, no.
Ryzen offers a better SMT implementation, or so the benchmarks show! I think you have to admit that is exactly what it means.
I just explained above why better SMT yields doesn't imply better SMT implementation. Check also the image that I prepared for illustration. Both cores in the image have the same SMT implementation but core B has higher SMT yields than core A. Core B has 100% SMT yields, whereas core A has only 50% yields.
One of the benchmarks from him illustrates my point nicely. Kabylake core has higher IPC than Haswell core, and Haswell higher than Zen core when running a single thread.
Then when loading a second thread, the Zen core obtains 13% more performance, whereas Haswell and Kabylake obtains only 7% and 3%.
Of course, one cannot take those SMT yields and claim that Haswell has a twice better SMT implementation than Kabylake. Both Haswell and Skylake have virtually the same SMT implementation. The difference is that the Kabylake core has most of its execution resources already running a thread, and loading second thread on the same core only increase performance by 3%, because there is no more resources free to execute this second thread.
The same happens with the Zen core. Zen doesn't have a better SMT implementation than Intel, but worse IPC for one thread, which leaves more room for executing a second thread. That is why a second thread improves the performance by 13% on Zen core.
I just explained above why better SMT yields doesn't imply better SMT implementation. Check also the image that I prepared for illustration. Both cores in the image have the same SMT implementation but core B has higher SMT yields than core A. Core B has 100% SMT yields, whereas core A has only 50% yields.
One of the benchmarks from him illustrates my point nicely. Kabylake core has higher IPC than Haswell core, and Haswell higher than Zen core when running a single thread.
Then when loading a second thread, the Zen core obtains 13% more performance, whereas Haswell and Kabylake obtains only 7% and 3%.
Of course, one cannot take those SMT yields and claim that Haswell has a twice better SMT implementation than Kabylake. Both Haswell and Skylake have virtually the same SMT implementation. The difference is that the Kabylake core has most of its execution resources already running a thread, and loading second thread on the same core only increase performance by 3%, because there is no more resources free to execute this second thread.
The same happens with the Zen core. Zen doesn't have a better SMT implementation than Intel, but worse IPC for one thread, which leaves more room for executing a second thread. That is why a second thread improves the performance by 13% on Zen core.
The SMT implementation is different. You show that very well will pictures. Simplified all computing is going to have trade-offs depending on what you are trying accomplish. And then you gain IPC through uArch improvements/software optimization to perform certain tasks, or "tuning" if that is what we want to call it. I've mentioned this before in this thread with measurements look at the single thread and multi-thread test.: http://www.tomshardware.com/forum/id-3327589/amd-ryzen-megathread-faq-resources/page-41.html#20123237
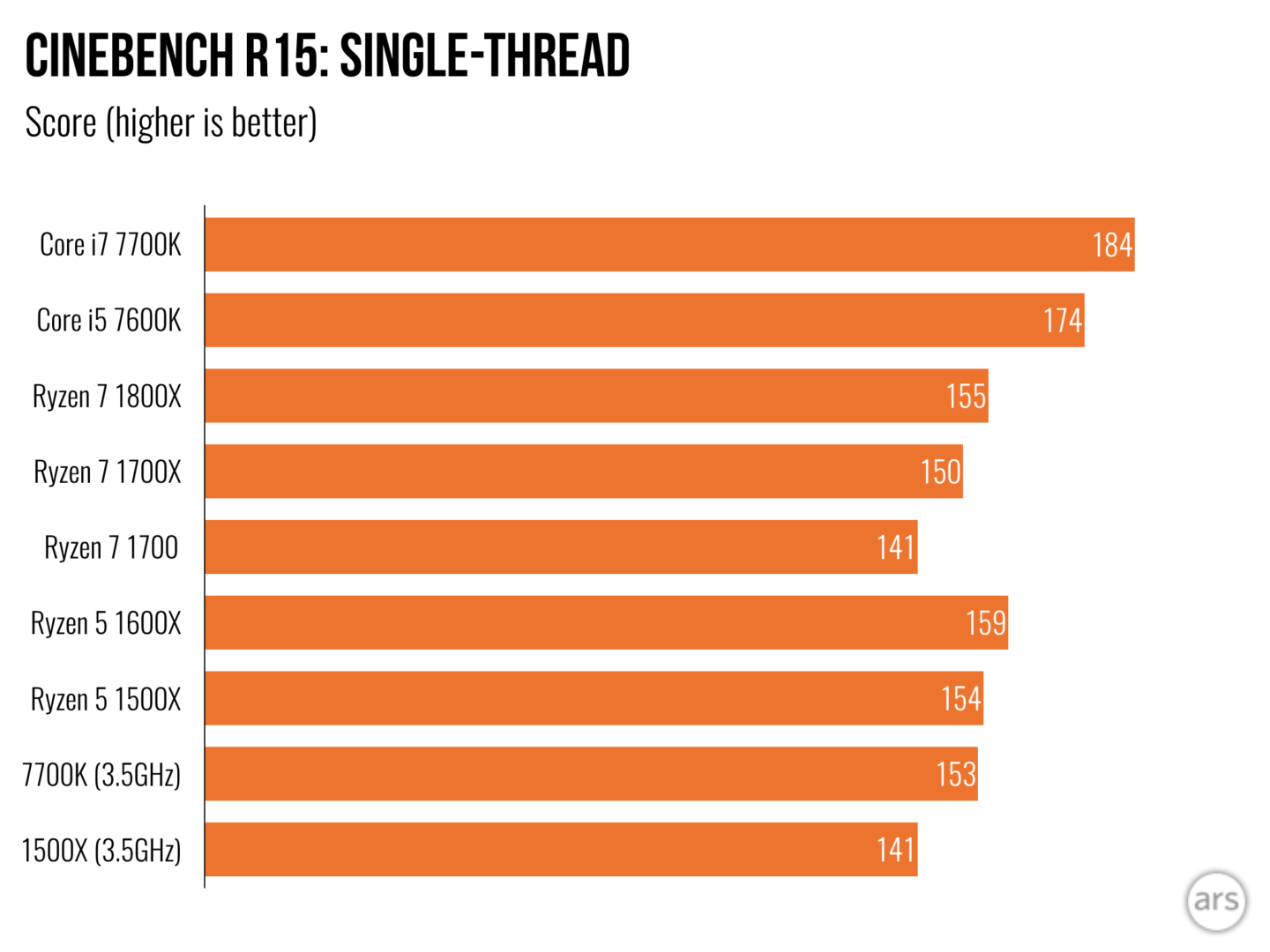
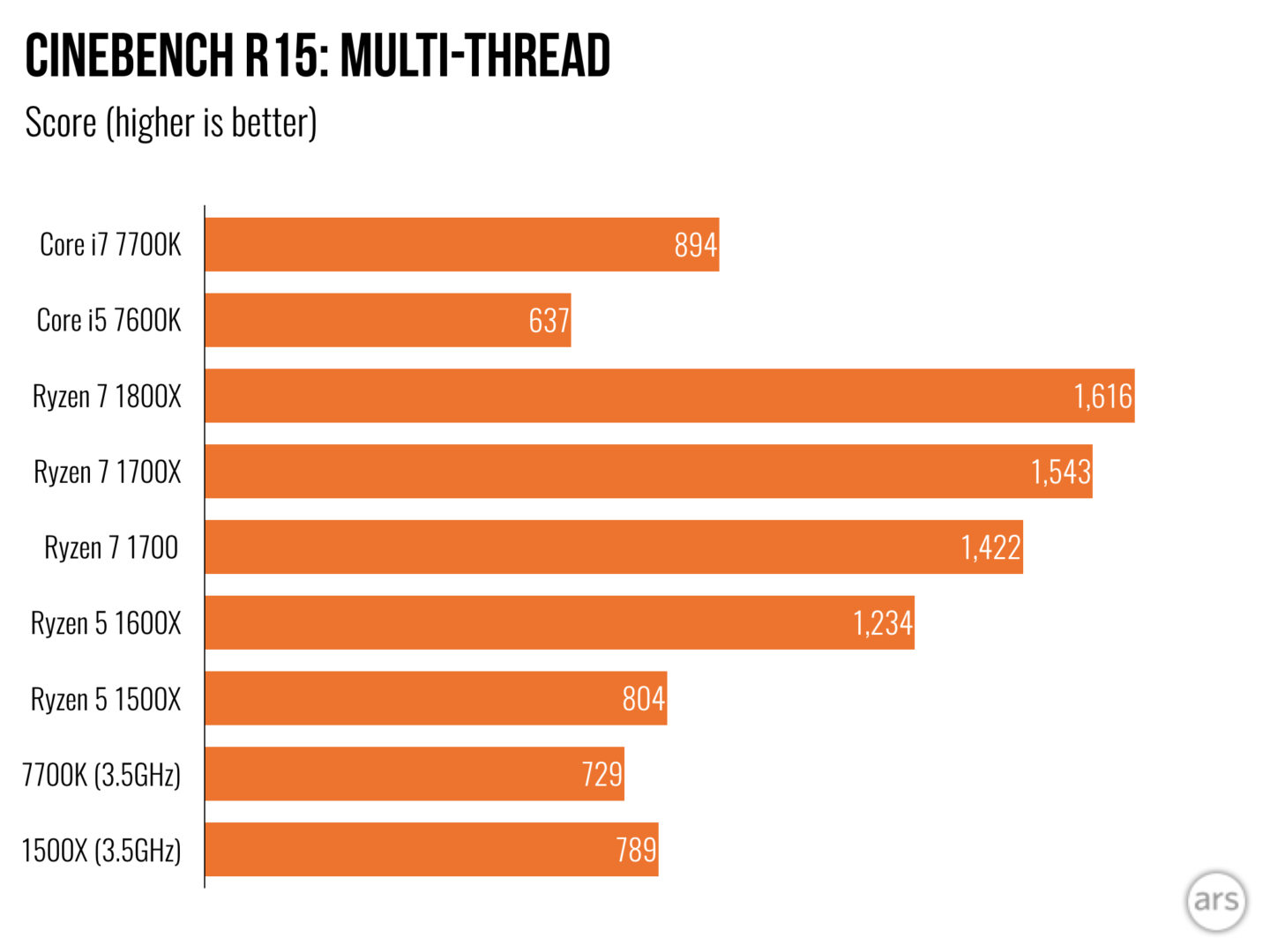
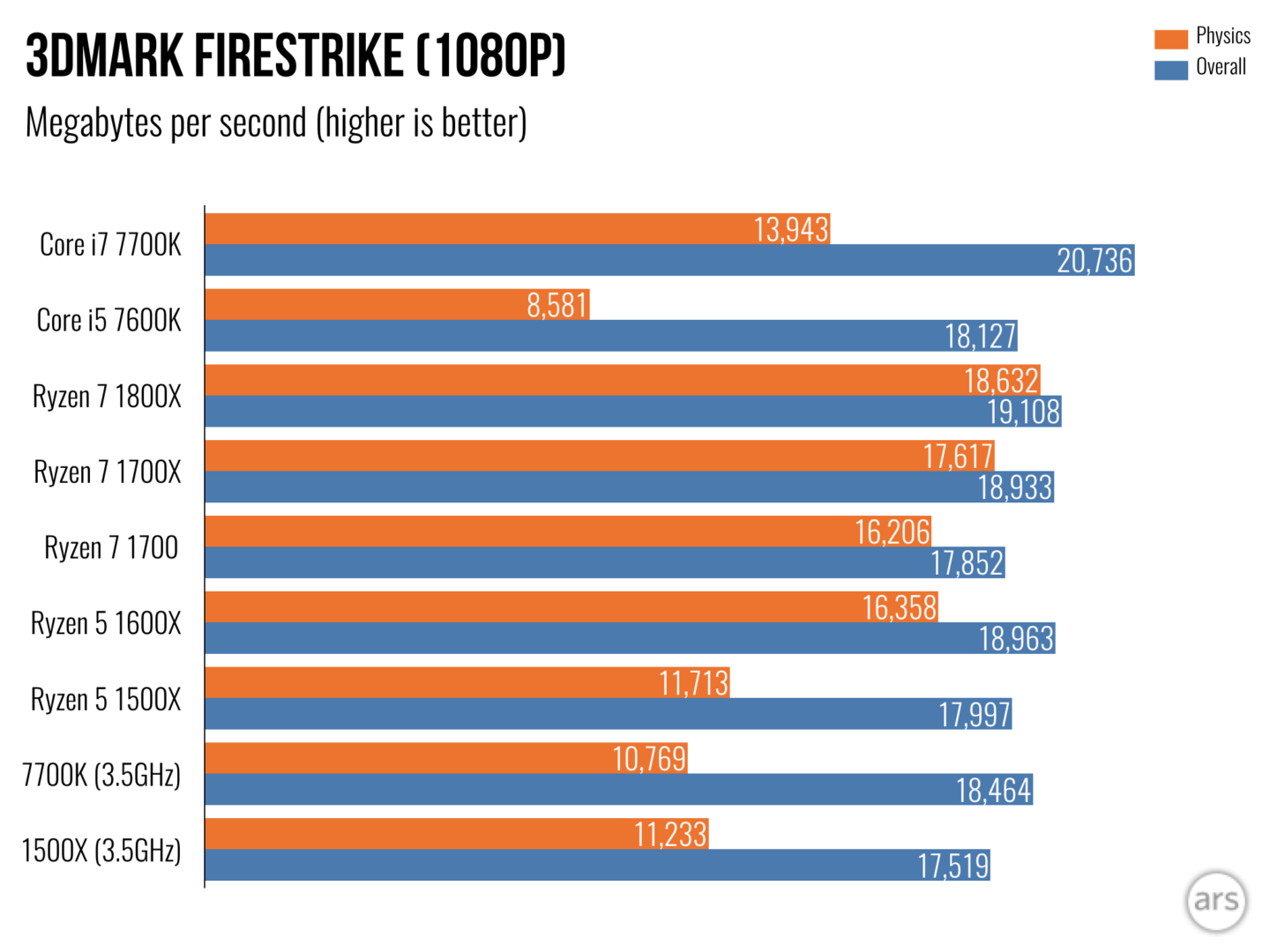
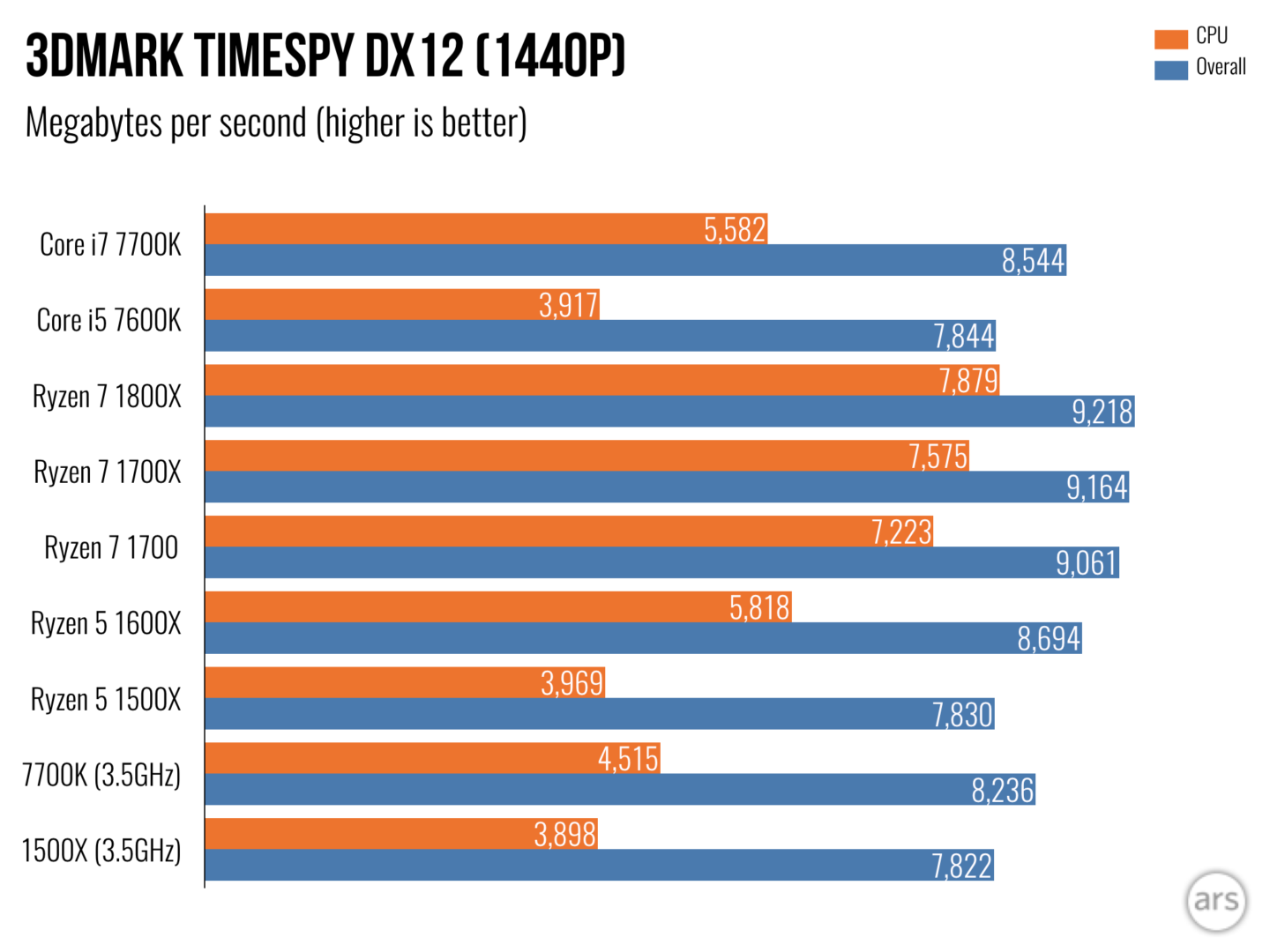
-8.5% 1500X@3.5GHz vs 7700k@3.5GHz
+8.2% 1500X@3.5GHz vs 7700k@3.5GHz
+4.3% 1500X@3.5GHz vs 7700k@3.5GHz in Physics showing Ryzens superior number crunching vs. Intel
-5.3% 1500X@3.5GHz vs 7700k@3.5GHz overall
But look at the 7600k with a base clock of 3.8GHz, which is 8.5% faster than the 1500X
+30.9% 1500X@3.5GHz vs 7600K@3.8GHz
-3.4% 1500X@3.5GHZ vs 7600K@3.8GHz
-5.2% 1500X@3.5GHz vs 7700K@3.5GHz overall
But look at the 7600k with a base clock of 3.8GHz, which is 8.5% faster than the 1500X
0.2% 1500X@3.5GHz vs 7600K@3.8GHz overall
This is first generation Ryzen, it will undoubtedly take years to optimize uArch/software to improve performance with all application. Some synthetics show a lot of raw performance that isn't being utilized by programs. AMD developed Ryzen chips to have superior multithreading clock for clock, by virtue of their implementation of SMT, which you illustrate very well with pictures. AMD also advertised that, and that is what it was trying to accomplish. Ryzen's 1800X($450) was made to compete with Intel's 6900X($1,100) which it did compete against very well despite only having dual channel RAM. The 1700 is arguably the much better buy because it was only about couple hundred MHz difference in processor speed overlocked, which could be bought for $310 and came with a cooler capable over overclocking to 3.8GHz. This is what made Ryzen so amazing.
On average once you gather a good 50 applications one will find IPC between sandy and haswell on average i spent days doing that comparing several sites which used 3200mhz memory as a base line.
I expected IPC to be lower then sandy before Ryzen released i was happy to be wrong. I own the build i ran benchmarks that historically sucked on Amd yet Ryzen always matches sandy or higher, Ryzen's number one issue for us enthusiasts is clock speed with IPC being second. I fear Amd will just throw more cores at the problem and i hope they don't do that alone i want them to focus on their weaknesses instead of their strengths.
But yes some users claimed some big statements about Zen and continue to use conspiracy theories to say it's true. I have no idea why anyone does this. I can tell you all 3 companies have been troublesome to us enthusiasts who want more for their money and to see innovation if i had to say who was probably the best at not doing that i would say Nvidia however i'll admit they do it too somewhat.
No competition means very little to no improvements in most cases and i feel Intel took advantage of this and seen it as an opportunity when they saw FX. This is why we saw 4 cores as their mainstream CPU for so long.
Here we go again with IPC fights. Cherrypicked applications can show from no IPC gap to 50% gap (depending on who cherrypicks). hardware.fr did a recent comparison between 4 and 6 core coffe lake vs 4 and 6 core ryzen. All of them at 3.5GHz. It's probably the most extensive IPC comparisson that I've seen (12 applications).
The average shows that the gap is only 11% for 6-core and 15% for 4 core. That is an interesting result. it looks like Ryzen scales better with extra cores.
The average shows that the gap is only 11% for 6-core and 15% for 4 core. That is an interesting result. it looks like Ryzen scales better with extra cores.
The average shows that the gap is only 11% for 6-core and 15% for 4 core. That is an interesting result. it looks like Ryzen scales better with extra cores.
So as we all knew six months before it released: Haswell IPC.
Actually, when it comes to computing, Zen is between Ivy Bridge and Haswell on average. When it comes to games, it's between Sandy Bridge and Ivy Bridge on average.
The average shows that the gap is only 11% for 6-core and 15% for 4 core. That is an interesting result. it looks like Ryzen scales better with extra cores.
So as we all knew six months before it released: Haswell IPC.
Actually, when it comes to computing, Zen is between Ivy Bridge and Haswell on average. When it comes to games, it's between Sandy Bridge and Ivy Bridge on average.
This is exactly what I showed with the 7700K vs the 1500X.
That is the same 8.5% advantage the 7700K has for single thread, but you lack the graphs showing that the 1500X displays superior multi-threaded performance by 8.2%. Juangra shows the difference in SMT implementation between Kabey Lake and Ryzen accounting for the multi-threaded performance gains.
Here we go again with IPC fights. Cherrypicked applications can show from no IPC gap to 50% gap (depending on who cherrypicks). hardware.fr did a recent comparison between 4 and 6 core coffe lake vs 4 and 6 core ryzen. All of them at 3.5GHz. It's probably the most extensive IPC comparisson that I've seen (12 applications).
The average shows that the gap is only 11% for 6-core and 15% for 4 core. That is an interesting result. it looks like Ryzen scales better with extra cores.
Most likely that's over CCX latency more communication between cores with less cores per core complex can't wait to see desktop raven ridge as ccx latency won't be a concern for the CPU just a shame L3 cache is cut in half...least we have L3 cache on a APU this time however
The average shows that the gap is only 11% for 6-core and 15% for 4 core. That is an interesting result. it looks like Ryzen scales better with extra cores.
So as we all knew six months before it released: Haswell IPC.
Actually, when it comes to computing, Zen is between Ivy Bridge and Haswell on average. When it comes to games, it's between Sandy Bridge and Ivy Bridge on average.




































































 Twitter
Twitter