















-Fran- :
I'm going to use your same quoted statement:
Look at the bolded part. Read that again. Slowly.
AMD is making some claims about the performance of various Epyc products' performance today, and the initial outlook is good. However, we do have to take issue with a couple of the choices AMD made on the way to its numbers. After compiling SPECint_rate_base2006 with the -O2 flag in GCC, AMD says observed a 43% delta between its internal numbers for the Xeon E5-2699A v4 and public SPEC numbers for similar systems produced using binaries generated by the Intel C++ compiler. In turn, AMD applied that 43% (or 0.575x) across the board to some publicly-available SPECint_rate_base scores for several two-socket Xeon systems.
It's certainly fair to say that SPEC results produced with Intel's compiler might deserve adjustment, but my conversations with other analysts present at the Epyc event suggests that a 43% reduction is optimistic. The -O2 flag for GCC isn't the most aggressive set of optimizations available from that compiler, and SPEC binaries generated accordingly may not be fully representative of binaries compiled in the real world.
Look at the bolded part. Read that again. Slowly.
I know that bolded part. It just correspond to this part of my former claim
The reason why most submissions use ICC is because it is almost guaranteed to provide the highest scores due to extracting more performance from the hardware.
I will say it again. The problem is not that ICC provides higher scores than GCC. We have know this for many years.¶ The problem is that the gap between GCC and ICC is not 43%, and the scores that AMD estimated for Xeons are all wrong.
-Fran- :
Also, GCC discourages to run the compiler with O3, so O2 is the safe optimization level for any server compiled workload using GCC. Mentioning that it supports O3 or even specific uArch extensions is tricky, to say the least. If you want your binary to be CPU bound, you can do that easily playing with the uArch flags, that is what ICC does anyway, but automatically for Intel CPUs. Hence, the "correction" AMD is applying to the results. I won't say they did not cherry pick, but that is expected out of any company.
Irrelevant. No one is objecting on the flags used during compiling. The problem is that the scores that AMD assigns to the chips from the competence don't correspond to reality.
NOTE:
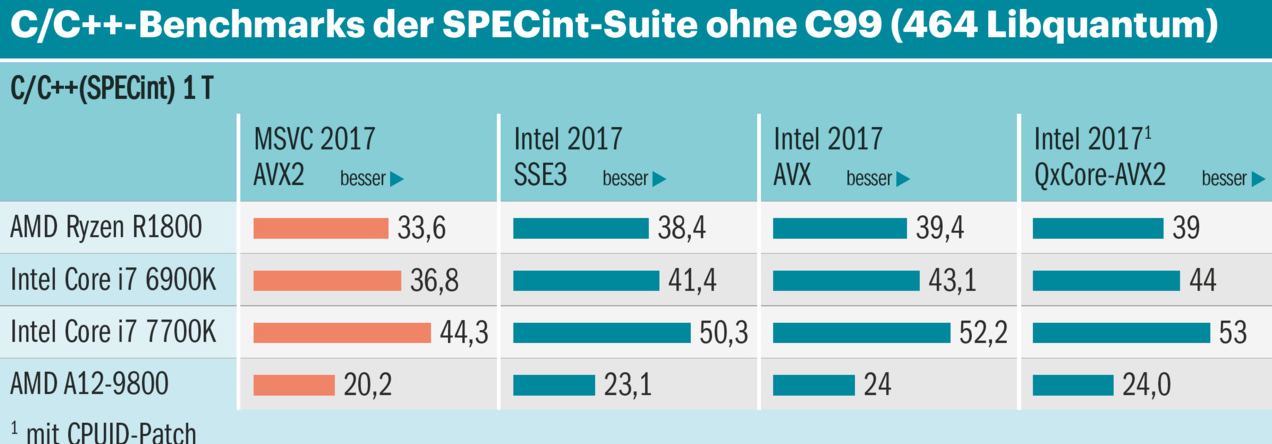
¶ In the first page of this PDF you can find a figure with corrected SPECint scores. You can see the gap is estimated to be 10%. In more recent times the gap is usually considered to be 15%. It is not the 43% that AMD pretends.



































 Twitter
Twitter