Discussion: AMD Ryzen
Page 77 - Seeking answers? Join the Tom's Hardware community: where nearly two million members share solutions and discuss the latest tech.
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
- Status
- Not open for further replies.








I downloaded the new database from OCUK for the Zen Blender Render all samples I am submitting here are done with CPU clocks close to or exactly 4.5ghz on 100 samples:
i5 2500K(4.5ghz) - 70 seconds (CB 127/461)
i5 3570K(4.4ghz) - 68 seconds (CB 132/510)
i5 4690(4.5ghz) - 52 seconds (CB 152/534)
i5 6600K(4.5ghz) - 50 seconds (CB 166/600)
Major performance leap from Ivy to Haswell
i7 2600K(4.5ghz) - 49 seconds (CB 128/612)
i7 3770K(4.6ghz) - 43 seconds (CB 137/672)
i7 4770K(4.5ghz) - 37 seconds (CB 141/709)
i7 4790K(4.4ghz) - 39 seconds (CB 169/854)
i7 6700K(4.4ghz) - 36 seconds (CB 180/888)
Again there is a leap to haswell but the extent of SMT is actually less than single thread performance. On SMT alone the Haswell is only marginally slower than the 6700K despite CB showing a gains in SMT.
The logical conclusion is that Blender is not that dependent on number of threads but rather the strength of architecture, 20 bad cores equate to bad performance in ST and MT metrics and the easiest way to prove that is to post AMD results.
Summary:
i5 6600K can match the SMT on a 2600K, it is done on improved architectural gains, the underlying premise is that slow architecture equals slower performance in single threaded and multi threaded.
(All CPU scores off 4.6Ghz)
FX 4100 -198
FX 6300 - 104
FX 8350 - 75
X6 1100T @ 4ghz - 68
That proves that Thuban had rather strong single thread given its age it was able to at least be relevant to a Sandy based 2500K at lower clocks and the two extra physical cores. Bulldozer is a complete disaster on the other hand, slower than the Phenom II and with scaling very poor on very poor single thread perfromance. FX8350 is 8 physical processors producing less than 4 at higher clocks.
I rest my case, multi threaded performance is affected by strength of the uarch, Single thread and Multi thread is a product of IPC on a application to application basis, performance between single and multi thread is mutually affected and SMT ratio is different application to application.
What I am asking for is proof that Ryzen has higher SMT than Intel when per CPC the 6900K held a comfortable lead, even after dresdenboy altered clocks to final silicon levels the 6900K is still 10% faster in SMT domain. The answer is clear as day and as told by ShockG, Ryzen can beat haswell but it is not fast enough to beat Broadwell E in any domain. AMD with CMT that already scales higher than SMT could not match the SMT on a sandy, what evidence is there that AMD can on their first ever SMT design beat Intel and a broadwell E by 10%.
i5 2500K(4.5ghz) - 70 seconds (CB 127/461)
i5 3570K(4.4ghz) - 68 seconds (CB 132/510)
i5 4690(4.5ghz) - 52 seconds (CB 152/534)
i5 6600K(4.5ghz) - 50 seconds (CB 166/600)
Major performance leap from Ivy to Haswell
i7 2600K(4.5ghz) - 49 seconds (CB 128/612)
i7 3770K(4.6ghz) - 43 seconds (CB 137/672)
i7 4770K(4.5ghz) - 37 seconds (CB 141/709)
i7 4790K(4.4ghz) - 39 seconds (CB 169/854)
i7 6700K(4.4ghz) - 36 seconds (CB 180/888)
Again there is a leap to haswell but the extent of SMT is actually less than single thread performance. On SMT alone the Haswell is only marginally slower than the 6700K despite CB showing a gains in SMT.
The logical conclusion is that Blender is not that dependent on number of threads but rather the strength of architecture, 20 bad cores equate to bad performance in ST and MT metrics and the easiest way to prove that is to post AMD results.
Summary:
i5 6600K can match the SMT on a 2600K, it is done on improved architectural gains, the underlying premise is that slow architecture equals slower performance in single threaded and multi threaded.
(All CPU scores off 4.6Ghz)
FX 4100 -198
FX 6300 - 104
FX 8350 - 75
X6 1100T @ 4ghz - 68
That proves that Thuban had rather strong single thread given its age it was able to at least be relevant to a Sandy based 2500K at lower clocks and the two extra physical cores. Bulldozer is a complete disaster on the other hand, slower than the Phenom II and with scaling very poor on very poor single thread perfromance. FX8350 is 8 physical processors producing less than 4 at higher clocks.
I rest my case, multi threaded performance is affected by strength of the uarch, Single thread and Multi thread is a product of IPC on a application to application basis, performance between single and multi thread is mutually affected and SMT ratio is different application to application.
What I am asking for is proof that Ryzen has higher SMT than Intel when per CPC the 6900K held a comfortable lead, even after dresdenboy altered clocks to final silicon levels the 6900K is still 10% faster in SMT domain. The answer is clear as day and as told by ShockG, Ryzen can beat haswell but it is not fast enough to beat Broadwell E in any domain. AMD with CMT that already scales higher than SMT could not match the SMT on a sandy, what evidence is there that AMD can on their first ever SMT design beat Intel and a broadwell E by 10%.














The numbers are not fluke or cherry picked, they are extremely telling that it can run with a BDW E while being in testing phase, that there are no final clocks and the performance already matched a i7 5960X and why Blender is very telling on performance in that Ryzen at 150 samples is considerably faster than the FX8350 at 100 samples and 4.6Ghz clock speed. This is generally indicative of a very fast uArch.

To the answer, but a i5 6600K is faster than a Ryzen, yes it is, and 4 Core CPU's beating more threaded CPU's is not anything new, here is an i5 6600K beating a 5960X, 5820K, 4770K, 4790K and the list goes on.
AMD producing Sandy performance would be bad given that Sandy's place is represented in the Graph, it would be a bad product and impossible to sell, where would aMD want to be to ruffle a few feathers? exactly they want to make a statement and they have chosen the 6900K to make it, it performs like or around a 6900K because it is that fast, it is the statement AMD want to make to a statement of intent, to kind of let Intel know that they are being pursued.
To the answer, but a i5 6600K is faster than a Ryzen, yes it is, and 4 Core CPU's beating more threaded CPU's is not anything new, here is an i5 6600K beating a 5960X, 5820K, 4770K, 4790K and the list goes on.
AMD producing Sandy performance would be bad given that Sandy's place is represented in the Graph, it would be a bad product and impossible to sell, where would aMD want to be to ruffle a few feathers? exactly they want to make a statement and they have chosen the 6900K to make it, it performs like or around a 6900K because it is that fast, it is the statement AMD want to make to a statement of intent, to kind of let Intel know that they are being pursued.
Saga Lout :
Dont take this the wrong way fellows. I'm really am impressed by the knowledge I see displayed in this thread. What mystifies me some days is why you can't always agree on what seems to be fact. 😀
Keep the good work.
Keep the good work.
Agreeing is less fun 😛
cdrkf :
juanrga :
8350rocks :
Alright Juan...
You keep claiming 42% via SMT.
So explain to me how SMT on a core with less dedicated resources is going to get even remotely close to a core with almost twice as much dedicated resources to multithreading?
I do not see how a consistent ~50% gain from CMT is going to end up being marginally better than a core with half the resources, at best, dedicated to the additional cores...
I am pretty familiar with chip design...though I will admit I have not studied it deeply in a few years. However, you have to have resources to run the SMT to get those sorts of gains. PD showed that multithreading scales less than they expected...however...it scaled better than some expected.
So...AMD has slightly more hardware duplication than Intel...Intel typically sees a 20% gain-ish...I would expect something in the neighborhood of 25-30% based on the architecture differences, how are you arriving at 50% more gains from SMT than I am?
The 42% is the SMT yield measured by The Stilt on Haswell. His chip run a Blender bench on "127.98 seconds with 18C/18T while with SMT enabled the time was reduced to 90.07 seconds."
127.98 / 90.07 = 1.42
He got 27% yield for CB bench. The reason why Blender has higher SMT yields than other code is because there is lower ILP and more execution resources in the core are left for a second thread.
I expect Zen SMT yields to be about 10% higher than Haswell/Broadwell. I already explained the technical reasons why I think that Zen has lower IPC and higher SMT yields.
Other people also think similar to me regarding the more distributed nature of the Zen muarch. For instance this guy:
personally I still predict Ryzen will have greater SMT Yeild (%) than Broadwell, which means of course that throughput can be closer to Haswell/BW than it's ST performance is.
As for why I think this will be the case:- Distributed Int Schedulers, and a higher number of statically partitioned structures are the main reasons. Intel's more dynamic approach here should result in higher ST performance, but IMO is a mistake in regards to throughput perf/watt. if not perf/mm , It makes sense to me that AMD chose to avoid such a large unified scheduler.. This is after all an architecture designed to be as balanced as possible, But given it's 2017 now (Is here in Australia!) likely biased towards throughput wherever it didn't impact ST significantly,
Only detailed reviews of Zen will say if our hypothesis is correct or not.
I think it's also worth keeping in mind that *if* this is the case, it imo makes a lot more sense in 2017 than it did back when Bulldozer launched, as well as the fact that so far it looks like Zen doesn't push throughput to the total detriment of everything else. I still maintain that AMD don't have to exceed (or even outright match) Intel in IPC to have a successful product- what they need is a product that has strengths and also avoids significant weaknesses.
To be fair Bulldozer was supposed to launch with higher clocks. Glofo was unable to master the SOI process so well as IBM. Whereas IBM could launch 5GHz and higher server CPUs, Glofo has been able to launch a 5GHz octo-core only recently with a more mature process, and after increasing the TDP up to 220W.
The lower than expected clocks at launch killed ST performance on Bulldozer and derivatives.
sarinaide :
juanrga :
sarinaide :
The ES already matched a 5960X
True, on a specific set of GPU-like benches as H.264 and H.265, PovRay, Mental Ray, Blender,... Those benches have a low branching ratio, lots of threads to hide latencies, streaming-like prefetching profiles,...
It remains to be seen the performance on more typical CPU workloads, i.e. workloads with low explicit parallelism, many difficult to predict branches,...
To get the levels of SMT the stilt is trying to irrationally push it would take AMD to produce a scaling ratio of 8% over broadwell, and per CPC Broadwell has greater SMT scaling hence there is absolutely zero evidence that AMD are pushing server grade ST/MT levels.
The Stilt is not pushing anything. He only reported that his CPU run a Blender benchmark 42% faster with SMT activated.
And a 8% SMT scaling over Broadwell is perfectly admissible. There is no technical reason why it cannot be.
sarinaide :
I would be hesitant at taking the Stilt's word as gospel
No one is doing that.
sarinaide :
And again those benches are not affected by GPU aided performance.
No one said that are "affected by GPU aided performance". What was said is that those rendering/encoding benches are GPU-like code. They are throughput-optimized rather than latency-optimized. The nature of this kind of code is the reason why there are ports to run this kind of code on GPUs. Rendering code like Blender have ports to accelerate the execution on a GPU. This kind of code runs much faster on a GPU, because GPUs are throughput machines, whereas CPUs are optimized for latency and designed for a different kind of code.
The same about encoding. Not many time ago AMD gave talks on GPU-accelerated Handbrake and H.264:
Several weeks ago AMD dropped a bombshell: x264 and Handbrake would both feature GPU acceleration, largely via OpenCL, in the near future.
The reason why those applications are accelerated by a GPU is the same than for rendering. This kind of code runs much faster on a GPU, because GPUs are throughput machines, whereas CPUs are optimized for latency.
That is why I take CPCHardware review with a grain of salt. They compute benches consisted of a collection of rendering/encoding benchmarks. I am also suspicious that AMD chose Blender and Handbrake for the public demos of Zen. I am still awaiting proper CPU benches: i.e. benches that stress the branch unit, the prefetch system, the OOE logic,...
I would like to see a SPEC gcc run for Zen, for instance.
sarinaide :
Cinebech doesn't measure direct IPC, it is in their disclaimer.
CBST measures single thread performance. If we test two or more chips at same frequency, then we can compare their IPC. This is why reviews do stuff like this
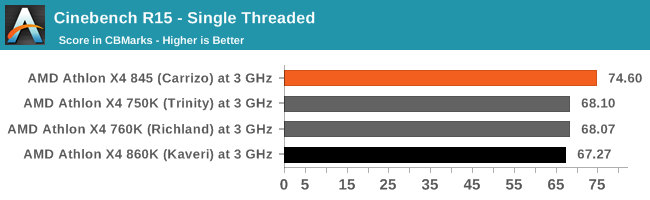
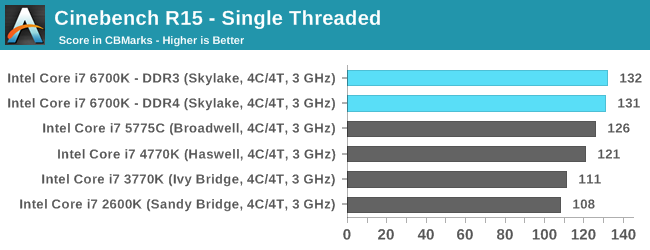
sarinaide :
You cannot take Cinebench and add 40% in a vacuum. When AMD talk of IPC gains it is at hardware level and how that is effected on Cinebench could easily be 60+ % gains if the uArch allows for more throughput. There is no 1:1 linearity in it.
We can add 40%. There not anything as "IPC gains at hardware level". As repetitively mentioned by gamerk (also by myself) the IPC varies from code to code. I mentioned how Skylake is about 20% faster than Sandy on CB, but Skylake is about 60% faster than Sandy on Dolphin.
When AMDs mention 40% they refer to average IPC. I measure the average IPC with CB. AMD also does. If you check past slides by AMD, they always use CB when discussing the average IPC of Kaveri, Carrizo, Bristol, and Zen. I have provided several of those slides. I can provide another now

cdrkf
Judicious
- Mar 18, 2013
- 3,146
- 423
- 36,240

























sarinaide :
That doesn't explain the 20% gap between a 6600k and 2500k.
6700K at 4.7Ghz
HT on 31s
HT off 46s
Diff% 39%
SMT results in gains but it isn't the only factor hence i5 6600k = i7 2600k with HTT
6700K at 4.7Ghz
HT on 31s
HT off 46s
Diff% 39%
SMT results in gains but it isn't the only factor hence i5 6600k = i7 2600k with HTT
The SMT gain will be different for each specific uArch.
It would be interesting to look at the SMT gain on Sandy vs Sandy, Ivy vs Ivy etc...
Also I don't really get the point you are making with the fact that a 4 thread 6600k can match an 8 thread 2600k- it is after all 4 generations newer. The HTT masks the difference somewhat compared to the results you get if you compare against the 2500k which is the direct comparison point.
At the end of the day, Is this something we can agree upon? The relatively competitive price, that is.
From Forbes Magazine online:
"The top end 8-core parts, similar to Intel's $1,000 Core i7-6900K, are expected to retail between $580 and $720, I've seen rumors of 6-core parts with 12 threads, similar to Intel's $600 Core i7-6850K retailing for around $250 and the SR3 - potentially a 4-core part with 8 threads has been rumored to land at around $150, with Intel's current equivalent being the Core i5-7600K, which retails for $100 more.
From Forbes Magazine online:
"The top end 8-core parts, similar to Intel's $1,000 Core i7-6900K, are expected to retail between $580 and $720, I've seen rumors of 6-core parts with 12 threads, similar to Intel's $600 Core i7-6850K retailing for around $250 and the SR3 - potentially a 4-core part with 8 threads has been rumored to land at around $150, with Intel's current equivalent being the Core i5-7600K, which retails for $100 more.
mono1029 :
At the end of the day, Is this something we can agree upon? The relatively competitive price, that is.
From Forbes Magazine online:
"The top end 8-core parts, similar to Intel's $1,000 Core i7-6900K, are expected to retail between $580 and $720, I've seen rumors of 6-core parts with 12 threads, similar to Intel's $600 Core i7-6850K retailing for around $250 and the SR3 - potentially a 4-core part with 8 threads has been rumored to land at around $150, with Intel's current equivalent being the Core i5-7600K, which retails for $100 more.
From Forbes Magazine online:
"The top end 8-core parts, similar to Intel's $1,000 Core i7-6900K, are expected to retail between $580 and $720, I've seen rumors of 6-core parts with 12 threads, similar to Intel's $600 Core i7-6850K retailing for around $250 and the SR3 - potentially a 4-core part with 8 threads has been rumored to land at around $150, with Intel's current equivalent being the Core i5-7600K, which retails for $100 more.
The last rumors mentioned pricing in the 3999--4999 RMB ($580--720) range for the 8C/16T model and that there is no 6C Zen. An older leaked slide priced the SR3 model above RMB1500 (above $220).
jaymc
Distinguished
- Dec 7, 2007
- 614
- 9
- 18,985









Correct me if i'm wrong but AMD cannot modify the SMT hardware on the SOC once it's released.
If that is the case then why wouldn't they have server grade SMT built in... I've seen this point raised but I mean aren't intending to try and make a dint in the server market. ??? Isn't there huge profit to be made in the explosion of server farms popping everywhere... if it get's any cloudier well all need umbrellas 🙂
After saying that think we could be in for an IPC surprise as well... but from their point of view isn't there more profit in the server market.. I mean sure they focused on both while designing the chip but if the knew they were targeting the server market, why would anyone think that they wouldn't put server grade SMT in there from the get go ???
J
If that is the case then why wouldn't they have server grade SMT built in... I've seen this point raised but I mean aren't intending to try and make a dint in the server market. ??? Isn't there huge profit to be made in the explosion of server farms popping everywhere... if it get's any cloudier well all need umbrellas 🙂
After saying that think we could be in for an IPC surprise as well... but from their point of view isn't there more profit in the server market.. I mean sure they focused on both while designing the chip but if the knew they were targeting the server market, why would anyone think that they wouldn't put server grade SMT in there from the get go ???
J
I believe I have found a formula to calculate 1 core performance on Blender.
Test chip i5 4460, base clock 3.2Ghz, 1 core turbo 3.4Ghz, all core turbo 3.3Ghz
Images of CPU-Z for validation
4 core time ~ 1:58 = 117s (rounded off)
1 core time ~ 7:35 = 456s (rounded off)
117 x (4/1) x (3.3/3.4) = 454s or 7m35s
I will need more people to test this to get accuracy on it but applying this so far to Ryzen
36 x 8/1 x 3.4/3.4 = 288s
*AMD had no turbo running so the clocks were locked to 3.4*
Applying that to the i7 5960X
@stock = 302s (all core turbo 3.3/ single core turbo 3.5)
Applying that to the 6900K
@Stock (3.5/3.7) = 272 [Note: i am not sure if the all core is 3.5 or 3.7]
5960X<4.5% SR7 < 5.4% 6900K
Test chip i5 4460, base clock 3.2Ghz, 1 core turbo 3.4Ghz, all core turbo 3.3Ghz
Images of CPU-Z for validation
4 core time ~ 1:58 = 117s (rounded off)
1 core time ~ 7:35 = 456s (rounded off)
117 x (4/1) x (3.3/3.4) = 454s or 7m35s
I will need more people to test this to get accuracy on it but applying this so far to Ryzen
36 x 8/1 x 3.4/3.4 = 288s
*AMD had no turbo running so the clocks were locked to 3.4*
Applying that to the i7 5960X
@stock = 302s (all core turbo 3.3/ single core turbo 3.5)
Applying that to the 6900K
@Stock (3.5/3.7) = 272 [Note: i am not sure if the all core is 3.5 or 3.7]
5960X<4.5% SR7 < 5.4% 6900K
8350rocks
Distinguished
- Mar 14, 2013
- 6,235
- 0
- 18,460










juanrga :
sarinaide :
juanrga :
sarinaide :
The ES already matched a 5960X
True, on a specific set of GPU-like benches as H.264 and H.265, PovRay, Mental Ray, Blender,... Those benches have a low branching ratio, lots of threads to hide latencies, streaming-like prefetching profiles,...
It remains to be seen the performance on more typical CPU workloads, i.e. workloads with low explicit parallelism, many difficult to predict branches,...
To get the levels of SMT the stilt is trying to irrationally push it would take AMD to produce a scaling ratio of 8% over broadwell, and per CPC Broadwell has greater SMT scaling hence there is absolutely zero evidence that AMD are pushing server grade ST/MT levels.
The Stilt is not pushing anything. He only reported that his CPU run a Blender benchmark 42% faster with SMT activated.
And a 8% SMT scaling over Broadwell is perfectly admissible. There is no technical reason why it cannot be.
sarinaide :
I would be hesitant at taking the Stilt's word as gospel
No one is doing that.
sarinaide :
And again those benches are not affected by GPU aided performance.
No one said that are "affected by GPU aided performance". What was said is that those rendering/encoding benches are GPU-like code. They are throughput-optimized rather than latency-optimized. The nature of this kind of code is the reason why there are ports to run this kind of code on GPUs. Rendering code like Blender have ports to accelerate the execution on a GPU. This kind of code runs much faster on a GPU, because GPUs are throughput machines, whereas CPUs are optimized for latency and designed for a different kind of code.
The same about encoding. Not many time ago AMD gave talks on GPU-accelerated Handbrake and H.264:
Several weeks ago AMD dropped a bombshell: x264 and Handbrake would both feature GPU acceleration, largely via OpenCL, in the near future.
The reason why those applications are accelerated by a GPU is the same than for rendering. This kind of code runs much faster on a GPU, because GPUs are throughput machines, whereas CPUs are optimized for latency.
That is why I take CPCHardware review with a grain of salt. They compute benches consisted of a collection of rendering/encoding benchmarks. I am also suspicious that AMD chose Blender and Handbrake for the public demos of Zen. I am still awaiting proper CPU benches: i.e. benches that stress the branch unit, the prefetch system, the OOE logic,...
I would like to see a SPEC gcc run for Zen, for instance.
While seeing a set of SPEC benches would be interesting...the big thing there is that it can be custom configured to show cherry picked examples where throughput reigns king, and can leave a completely confusing picture depending upon what you are wanting to see from SPEC.
Their suite is amazing...and depending upon who configured it, could make anything look like the second coming of Christ, or a complete cock up in the making.
8350rocks :
juanrga :
I would like to see a SPEC gcc run for Zen, for instance.
While seeing a set of SPEC benches would be interesting...the big thing there is that it can be custom configured to show cherry picked examples where throughput reigns king, and can leave a completely confusing picture depending upon what you are wanting to see from SPEC.
Their suite is amazing...and depending upon who configured it, could make anything look like the second coming of Christ, or a complete cock up in the making.
Similar stuff can be said about other benches as Blender or Handbrake. Blender results vary with the settings and image selected. Skylake is 20% faster than Sandy clock-for-clock on Handbrake LQ, but a 28.2% faster than Sandy on Handbrake HQ.
For SPEC I would want gcc compiler and similar flags to avoid cheating of broken subtests as libquantum. Or I would simply eliminate them and focus on rest of subtests.
sarinaide :
I believe I have found a formula to calculate 1 core performance on Blender.
Test chip i5 4460, base clock 3.2Ghz, 1 core turbo 3.4Ghz, all core turbo 3.3Ghz
Images of CPU-Z for validation
4 core time ~ 1:58 = 117s (rounded off)
1 core time ~ 7:35 = 456s (rounded off)
117 x (4/1) x (3.3/3.4) = 454s or 7m35s
I will need more people to test this to get accuracy on it but applying this so far to Ryzen
36 x 8/1 x 3.4/3.4 = 288s
Test chip i5 4460, base clock 3.2Ghz, 1 core turbo 3.4Ghz, all core turbo 3.3Ghz
Images of CPU-Z for validation
4 core time ~ 1:58 = 117s (rounded off)
1 core time ~ 7:35 = 456s (rounded off)
117 x (4/1) x (3.3/3.4) = 454s or 7m35s
I will need more people to test this to get accuracy on it but applying this so far to Ryzen
36 x 8/1 x 3.4/3.4 = 288s
First the data for the i5 is wrong. The i5 4460 has turbobin of 0/1/2/2. This implies there is no all-core turbo or, said in another way, the all-core clock is always 3.2GHz. But correcting this mistake changes little the result: 440s instead the above 454s.
Second, this equation is not considering the effect of SMT (the i5 doesn't have hyperthreading). Moreover, this equation is assuming a linear relationship between performance and core count, which is not true (Amdahl law). It has to be corrected with scaling factor K function of the number of cores, K = K (N).
The equation could be still used for comparing the performance of chips with similar core count and SMT, assuming the scaling factors are similar for the chips. But comparing a quad-core to a octo-core will be artificially increasing the performance of each core on the octo-core chip for compensating for the Amdahl law.
All of this are the reasons why the equation says us that one Zen core @3.4GHz would be nearly 60% faster than one Haswell core @3.3GHz
454 / 288 = 1.576
jaymc :
Correct me if i'm wrong but AMD cannot modify the SMT hardware on the SOC once it's released.
If that is the case then why wouldn't they have server grade SMT built in... I've seen this point raised but I mean aren't intending to try and make a dint in the server market. ??? Isn't there huge profit to be made in the explosion of server farms popping everywhere... if it get's any cloudier well all need umbrellas 🙂
After saying that think we could be in for an IPC surprise as well... but from their point of view isn't there more profit in the server market.. I mean sure they focused on both while designing the chip but if the knew they were targeting the server market, why would anyone think that they wouldn't put server grade SMT in there from the get go ???
J
If that is the case then why wouldn't they have server grade SMT built in... I've seen this point raised but I mean aren't intending to try and make a dint in the server market. ??? Isn't there huge profit to be made in the explosion of server farms popping everywhere... if it get's any cloudier well all need umbrellas 🙂
After saying that think we could be in for an IPC surprise as well... but from their point of view isn't there more profit in the server market.. I mean sure they focused on both while designing the chip but if the knew they were targeting the server market, why would anyone think that they wouldn't put server grade SMT in there from the get go ???
J
what do you mean by server grade smt?
both intel and amd cpus have same smt implemented in their respective server and consumer cpus.
juanrga :
sarinaide :
I believe I have found a formula to calculate 1 core performance on Blender.
Test chip i5 4460, base clock 3.2Ghz, 1 core turbo 3.4Ghz, all core turbo 3.3Ghz
Images of CPU-Z for validation
4 core time ~ 1:58 = 117s (rounded off)
1 core time ~ 7:35 = 456s (rounded off)
117 x (4/1) x (3.3/3.4) = 454s or 7m35s
I will need more people to test this to get accuracy on it but applying this so far to Ryzen
36 x 8/1 x 3.4/3.4 = 288s
Test chip i5 4460, base clock 3.2Ghz, 1 core turbo 3.4Ghz, all core turbo 3.3Ghz
Images of CPU-Z for validation
4 core time ~ 1:58 = 117s (rounded off)
1 core time ~ 7:35 = 456s (rounded off)
117 x (4/1) x (3.3/3.4) = 454s or 7m35s
I will need more people to test this to get accuracy on it but applying this so far to Ryzen
36 x 8/1 x 3.4/3.4 = 288s
First the data for the i5 is wrong. The i5 4460 has turbobin of 0/1/2/2. This implies there is no all-core turbo or, said in another way, the all-core clock is always 3.2GHz. But correcting this mistake changes little the result: 440s instead the above 454s.
Second, this equation is not considering the effect of SMT (the i5 doesn't have hyperthreading). Moreover, this equation is assuming a linear relationship between performance and core count, which is not true (Amdahl law). It has to be corrected with scaling factor K function of the number of cores, K = K (N).
The equation could be still used for comparing the performance of chips with similar core count and SMT, assuming the scaling factors are similar for the chips. But comparing a quad-core to a octo-core will be artificially increasing the performance of each core on the octo-core chip for compensating for the Amdahl law.
All of this are the reasons why the equation says us that one Zen core @3.4GHz would be nearly 60% faster than one Haswell core @3.3GHz
454 / 288 = 1.576
I wasn't comparing a i5, I was just using an i5 at the time to see if I could get math to calculate the 1 core run and it did.
I did run a 6900K, 5960X and the Ryzen, the equation also works for overclocks. It can possibly use a tweaking on SMT scaling.
All three octocores, Zen ~ 4% faster than the Haswell E and ~5% slower than Broadwell
Blender scales like a boss with clock speed and cores, you can mimick a i7 5820K's score on a i7 5960X's score. It is linear to the very last core. I think I am starting to love Blender and I think Kyle Bennet does to.
With Cinebench, if we consider the 1188 score leaked and one has to play around with the degree of SMT, I put in the base line single thread performance if Zen = Haswell and if Zen = Broadwell SMT and then run the equation on about 27% that Juan mentioned.
@3.1 - Haswell E - 124
@3.1 - Broadwell E - 128
SR7 with Haswell E SMT scaling = ~20% (9.55)
1188/9.55 = 124
SR7 with Broadwell E SMT scaling = ~25% (10.1)
1156/10.1 = 118
@27% SMT scaling
8*1.27= 10.16
1188/10.16 = 117
If it was something rediculous like 40% which there is no evidence of:
8*1.40 = 12
1188/12 = 99
@3.1 - Haswell E - 124
@3.1 - Broadwell E - 128
SR7 with Haswell E SMT scaling = ~20% (9.55)
1188/9.55 = 124
SR7 with Broadwell E SMT scaling = ~25% (10.1)
1156/10.1 = 118
@27% SMT scaling
8*1.27= 10.16
1188/10.16 = 117
If it was something rediculous like 40% which there is no evidence of:
8*1.40 = 12
1188/12 = 99
cdrkf
Judicious
- Mar 18, 2013
- 3,146
- 423
- 36,240
sarinaide :
With Cinebench, if we consider the 1188 score leaked and one has to play around with the degree of SMT, I put in the base line single thread performance if Zen = Haswell and if Zen = Broadwell SMT and then run the equation on about 27% that Juan mentioned.
@3.1 - Haswell E - 124
@3.1 - Broadwell E - 128
SR7 with Haswell E SMT scaling = ~20% (9.55)
1188/9.55 = 124
SR7 with Broadwell E SMT scaling = ~25% (10.1)
1156/10.1 = 118
@27% SMT scaling
8*1.27= 10.16
1188/10.16 = 117
If it was something rediculous like 40% which there is no evidence of:
8*1.40 = 12
1188/12 = 99
@3.1 - Haswell E - 124
@3.1 - Broadwell E - 128
SR7 with Haswell E SMT scaling = ~20% (9.55)
1188/9.55 = 124
SR7 with Broadwell E SMT scaling = ~25% (10.1)
1156/10.1 = 118
@27% SMT scaling
8*1.27= 10.16
1188/10.16 = 117
If it was something rediculous like 40% which there is no evidence of:
8*1.40 = 12
1188/12 = 99
If you take the 845 score and add 40% you get around 110 as well, tbh whichever way you slice it we end up at a similar score. It could be 10 to 20 points higher / lower either way depending on many factors including final clocks, per core ipc vs smt scaling and so on.
A few people have commented they are suspicious of AMD hiding the single thread benches- based on everything we know I'm guessing that is because on pure single thread Zen doesn't look as impressive vs Intel (although I'll bet looks fantastic vs AMD's last gen). It's fairly obvious though that Kaby Lake will have the edge in pure single thread performance whereas Zen can match Intel's current large cpu on a more even basis- so it makes for a more impressive showing. I can't say for sure, but I don't think there's anything to worry too much about on single thread- it'll be a huge improvement I think.
8350rocks
Distinguished
- Mar 14, 2013
- 6,235
- 0
- 18,460
cdrkf :
sarinaide :
With Cinebench, if we consider the 1188 score leaked and one has to play around with the degree of SMT, I put in the base line single thread performance if Zen = Haswell and if Zen = Broadwell SMT and then run the equation on about 27% that Juan mentioned.
@3.1 - Haswell E - 124
@3.1 - Broadwell E - 128
SR7 with Haswell E SMT scaling = ~20% (9.55)
1188/9.55 = 124
SR7 with Broadwell E SMT scaling = ~25% (10.1)
1156/10.1 = 118
@27% SMT scaling
8*1.27= 10.16
1188/10.16 = 117
If it was something rediculous like 40% which there is no evidence of:
8*1.40 = 12
1188/12 = 99
@3.1 - Haswell E - 124
@3.1 - Broadwell E - 128
SR7 with Haswell E SMT scaling = ~20% (9.55)
1188/9.55 = 124
SR7 with Broadwell E SMT scaling = ~25% (10.1)
1156/10.1 = 118
@27% SMT scaling
8*1.27= 10.16
1188/10.16 = 117
If it was something rediculous like 40% which there is no evidence of:
8*1.40 = 12
1188/12 = 99
If you take the 845 score and add 40% you get around 110 as well, tbh whichever way you slice it we end up at a similar score. It could be 10 to 20 points higher / lower either way depending on many factors including final clocks, per core ipc vs smt scaling and so on.
A few people have commented they are suspicious of AMD hiding the single thread benches- based on everything we know I'm guessing that is because on pure single thread Zen doesn't look as impressive vs Intel (although I'll bet looks fantastic vs AMD's last gen). It's fairly obvious though that Kaby Lake will have the edge in pure single thread performance whereas Zen can match Intel's current large cpu on a more even basis- so it makes for a more impressive showing. I can't say for sure, but I don't think there's anything to worry too much about on single thread- it'll be a huge improvement I think.
Haswell single thread performance is inline with *our* expectations...but much of the public will <mod edit> on the product for not being "equal". By showing that throughput matches or exceeds BW-E...they are gaining more positive press for now.
<You've been here long enough to know better than to use such language in these forums>
- Status
- Not open for further replies.
TRENDING THREADS
-

-
 AMD Ryzen 9 9950X vs Intel Core Ultra 9 285K Faceoff — it isn't even close
AMD Ryzen 9 9950X vs Intel Core Ultra 9 285K Faceoff — it isn't even close- Started by Admin
- Replies: 54
-
 Discussion What's your favourite video game you've been playing?
Discussion What's your favourite video game you've been playing?- Started by amdfangirl
- Replies: 4K
-
 Question Would upgrading my GPU make sense with my current system?
Question Would upgrading my GPU make sense with my current system?- Started by biruz117
- Replies: 10
-

Latest posts
-

-
Question PC/Display gives no signal after changing settings in BIOS
- Latest: Hardstuckwithmypc
-
Space.com is part of Future plc, an international media group and leading digital publisher. Visit our corporate site.
© Future Publishing Limited Quay House, The Ambury, Bath BA1 1UA. All rights reserved. England and Wales company registration number 2008885.
 Twitter
Twitter