- Nov 21, 2018
- 20,802
- 903
- 43,560























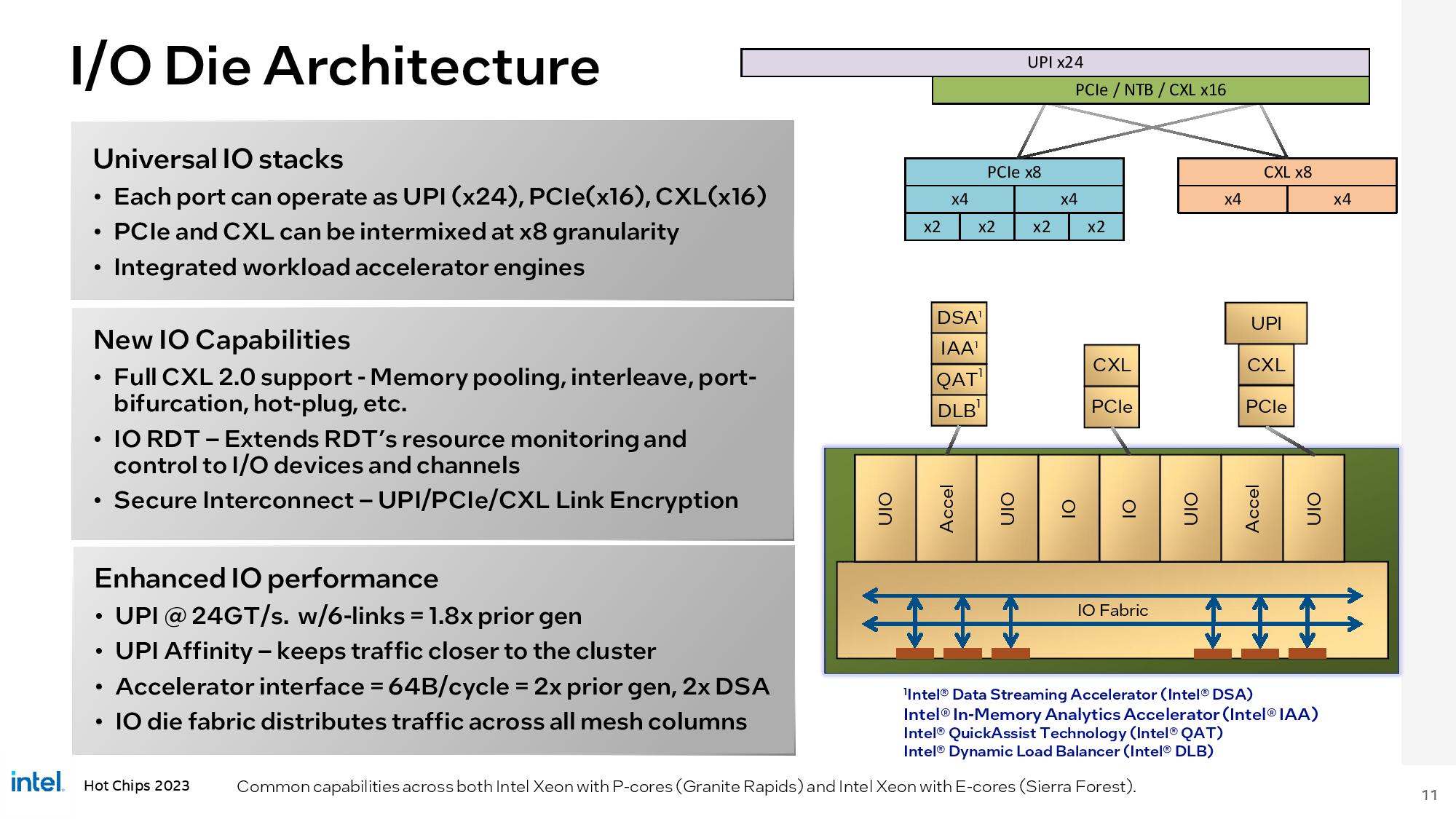
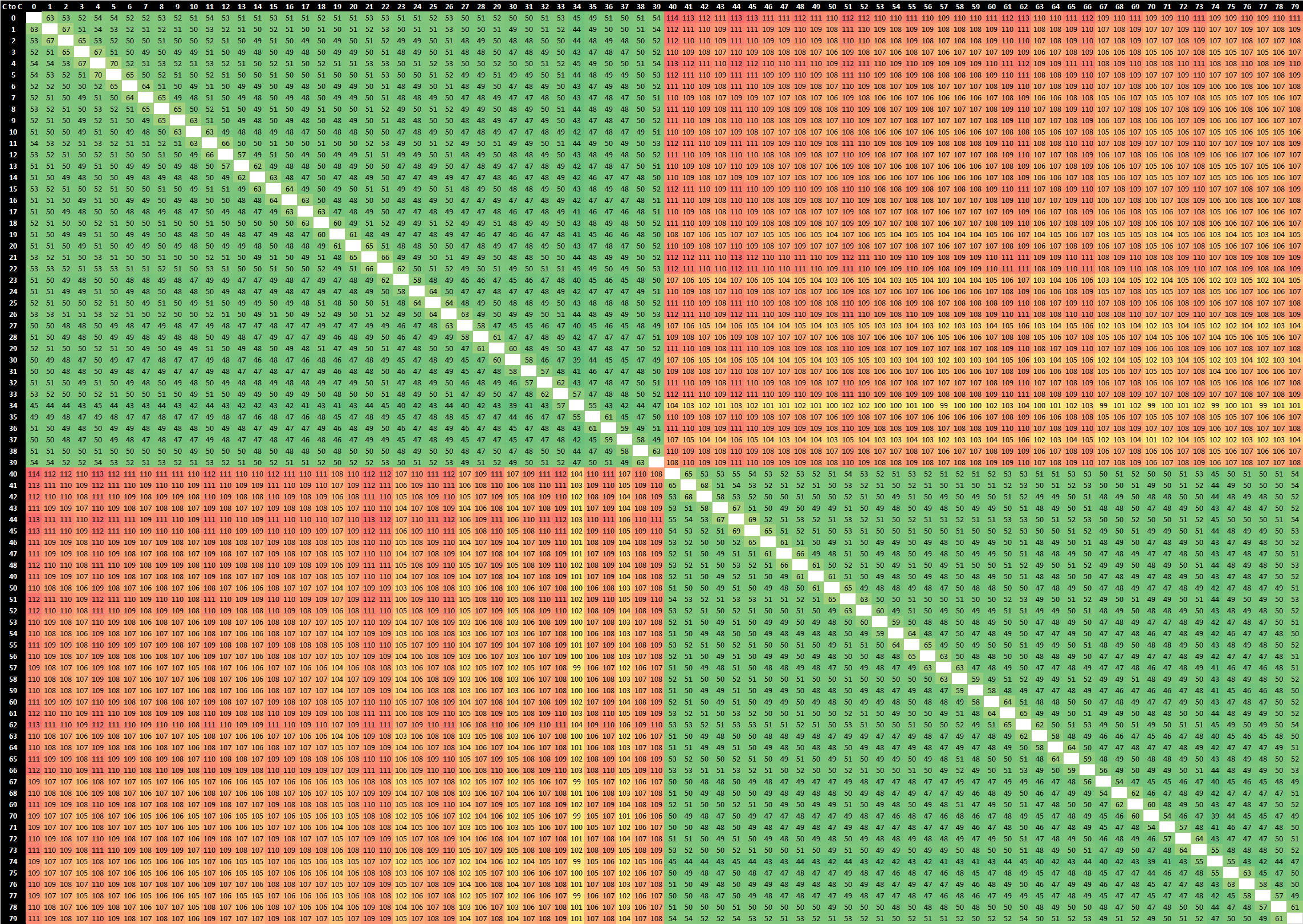
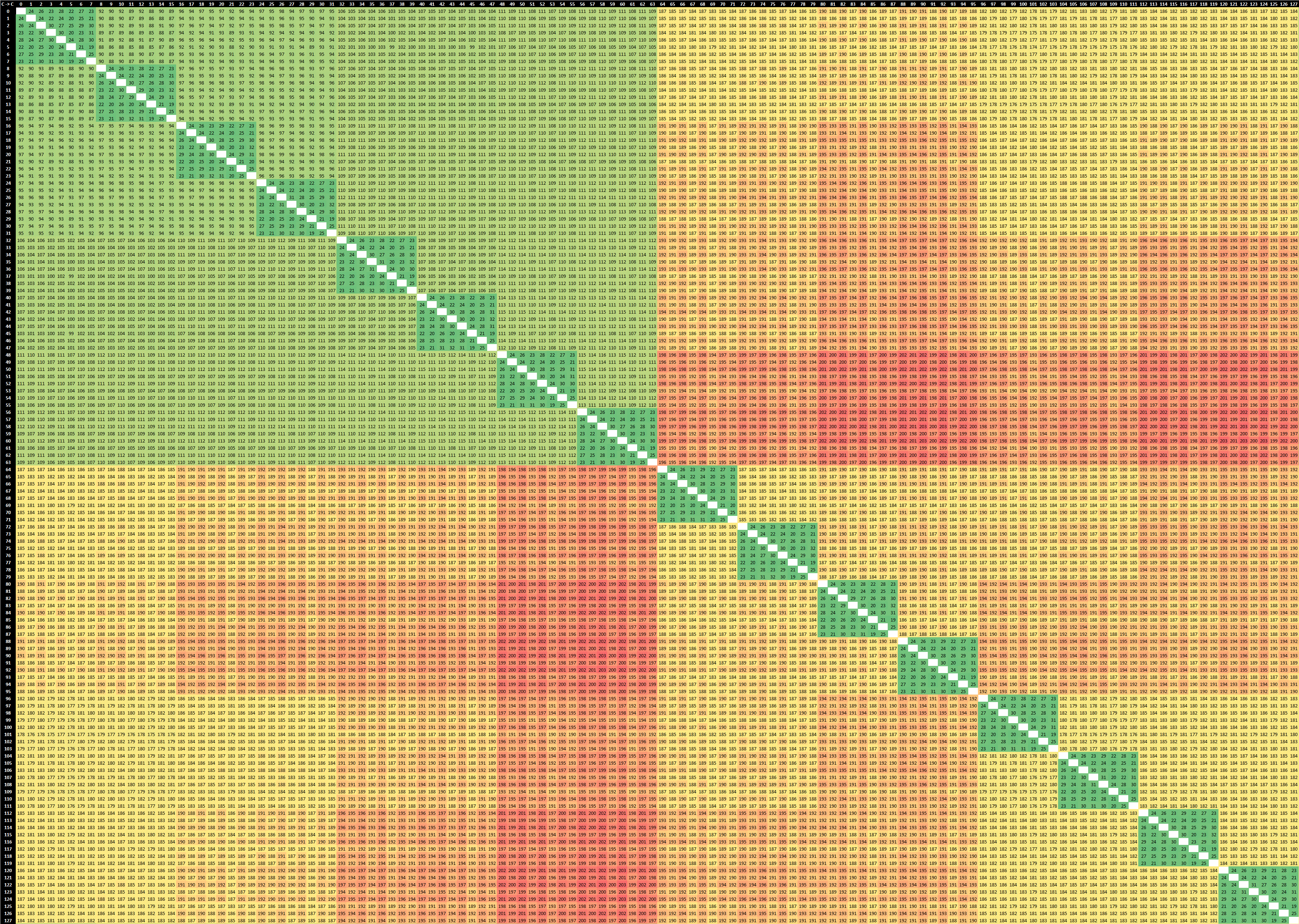
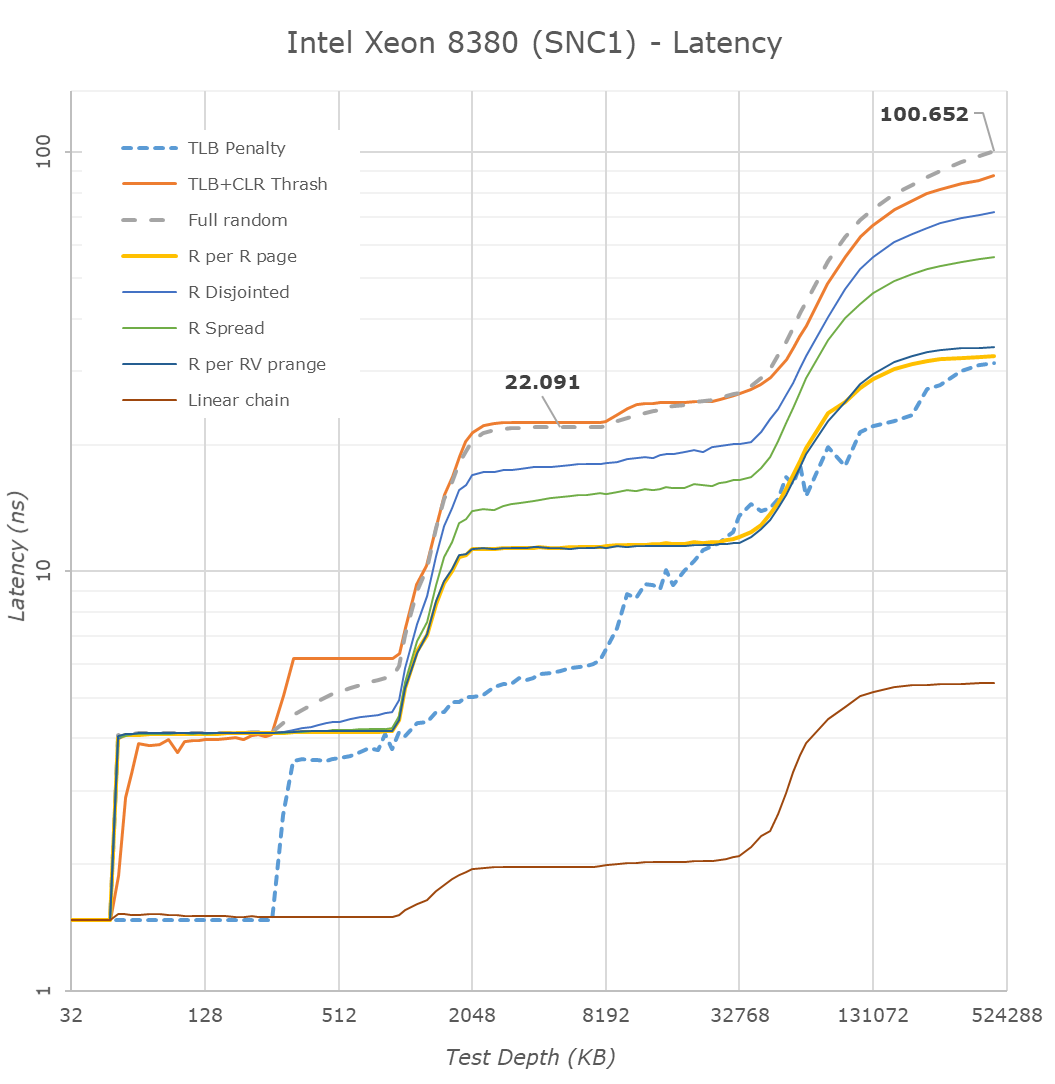
At Hot Chips 2023, Intel detailed the P- and E-Core architectures present in the future Xeon Sierra Forest and Granite Rapids processors.
Intel Details Sierra Forest and Granite Rapids Architecture, Xeon Roadmap : Read more
Intel Details Sierra Forest and Granite Rapids Architecture, Xeon Roadmap : Read more