News Intel Launches Sapphire Rapids Fourth-Gen Xeon CPUs and Ponte Vecchio Max GPU Series
Page 2 - Seeking answers? Join the Tom's Hardware community: where nearly two million members share solutions and discuss the latest tech.
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
Some of us would like to see more than 8P cores and 0E cores plus more memory channels and PCIe lanes. That's what we're hoping to get out of HEDT.A 24 core 13900k is $599 at newegg. I'm not sure what you're going on about "consumer HEDT will stay dead". Looks like it's alive and kicking to me.
-Fran-
Glorious
- May 3, 2007
- 9,557
- 3,106
- 47,640
























I just read the Phoronix review of SP and... Holy cow it's not good. You can tell this should've released last year. AMX does most of the heavy lifting for Intel, but who is running inference jobs on CPUs at the enterprise level anyway? And even then, it's not like AMD has bad performance for the price, considering it's not 2X the performance (over AMD), but it's almost 2X the price (not counting full rack, obviously).
Michael (from Phoronix) didn't include DB tests either, where the gap would also increase in favour of AMD for sure. So there's also that. Although that HBM2e "cache" should help a lot in DB apps. We'll see, but I think AMD may still have the advantage.
Regards.
Michael (from Phoronix) didn't include DB tests either, where the gap would also increase in favour of AMD for sure. So there's also that. Although that HBM2e "cache" should help a lot in DB apps. We'll see, but I think AMD may still have the advantage.
Regards.
I know that this is just a single benchmark, but AMD absolutely destroys Sapphire Rapids in it. Even AMDs last gen is faster:

 www.hardwaretimes.com
www.hardwaretimes.com
Dual Intel Sapphire Rapids-SP CPU Combo (120 Cores) Loses to a Single AMD Epyc Genoa CPU with 96 Cores | Hardware Times
Intel delayed its 4th Gen Xeon Sapphire Rapids Scalable processors by nearly a year. In the meantime, AMD released the Epyc Milan-X followed by the next-gen Genoa family based on the Zen 4 core architecture. Now that Sapphire Rapids is finally out in the market, Team Blue is having trouble...
www.hardwaretimes.com
jkflipflop98
Distinguished
- Feb 3, 2006
- 1,990
- 448
- 20,170












but who is running inference jobs on CPUs at the enterprise level anyway?
Pretty much every tech company on Earth.
-Fran-
Glorious
- May 3, 2007
- 9,557
- 3,106
- 47,640
Care to provide an example, please?Pretty much every tech company on Earth.
Regards.
To my knowledge, servers are usually running 24/7, so boot up time is not really relevant.
I had more in mind all IoT devices, laptop computers, tablets, desktop computers… that are also « at risk » in case of power failure (you lose everything you were working on).
Non-Volatile-Memory (NVM) like MRAM that would replace SRAM cache and DRAM would be disruptive and bring a paradigm shift : even when you shut down the computer (or in case of power failure), the data you were working on would still be there. Just put the power back-on and you start exactly where you left off (no need to reload all softwares and data in main memory). The notion of « booting your computer » would disappear.
Also for IoT devices, when there is no activity, even during weeks or months, the memory in standby would not consume power (add some power harvesting technologies, and you might have a remote IoT sensor device that could run for months / years)
No doubt in my mind that « Normally-off computing » is disruptive thanks to fast, low power, Non-Volatile-Memory (NVM) would bring many benefits.
Roland Of Gilead
Titan
- Aug 8, 2008
- 12,080
- 3,068
- 83,240



















we all know proof-reading isn't a thing at TH, but this article is shockingly poor.
'We'? Proof your post, before complaining about proofing
")







Hybrid sleep already accomplishes much the same thing. I.e. go to sleep when idle, with minimal power draw and near instant resume. Plus in the even of power loss, no data loss. I guess in places with poor power grids with frequent black/brown outs it'd be handy if you didn't want to get a UPS? I'm not sure having main memory be non volatile sufficient to guarantee no data loss on unexpected power loss though.I had more in mind all IoT devices, laptop computers, tablets, desktop computers… that are also « at risk » in case of power failure (you lose everything you were working on).
Non-Volatile-Memory (NVM) like MRAM that would replace SRAM cache and DRAM would be disruptive and bring a paradigm shift : even when you shut down the computer (or in case of power failure), the data you were working on would still be there. Just put the power back-on and you start exactly where you left off (no need to reload all softwares and data in main memory). The notion of « booting your computer » would disappear.
Also for IoT devices, when there is no activity, even during weeks or months, the memory in standby would not consume power (add some power harvesting technologies, and you might have a remote IoT sensor device that could run for months / years)
No doubt in my mind that « Normally-off computing » is disruptive thanks to fast, low power, Non-Volatile-Memory (NVM) would bring many benefits.
In general I don't see how further reducing/eliminating boot times would be a dramatic change, given that there's no reason to be be frequently (re)booting most devices in the first place. I rarely power down my PC, usually just put it to sleep.
I also doubt that NVM would replace on-die/package SRAM. It of course would depend on the performance of the hypothetical NVM tech, but it would be very difficult for socketed memory on the mobo to achieve the same speed/latency. Maybe if the NVM was also on-die/package, but then you have issues with capacity limits and upgrade-ability.
Last edited:
He also didn't use HBM2e or accelerators. Leaving more than a little performance on the table. It is more like a comparison of Nvidia to AMD where Nvidia turns off their cache, tensor and RTX cores.I just read the Phoronix review of SP and... Holy cow it's not good. You can tell this should've released last year. AMX does most of the heavy lifting for Intel, but who is running inference jobs on CPUs at the enterprise level anyway? And even then, it's not like AMD has bad performance for the price, considering it's not 2X the performance (over AMD), but it's almost 2X the price (not counting full rack, obviously).
Michael (from Phoronix) didn't include DB tests either, where the gap would also increase in favour of AMD for sure. So there's also that. Although that HBM2e "cache" should help a lot in DB apps. We'll see, but I think AMD may still have the advantage.
Regards.
Intel does state an average 2.9x improvement in perf/watt with the accelerators on vs the 8380 with the tests they ran. That's probably 50% more performance in general. Workloads targeted by the accelerators (4 of each):

might make Epyc look like the new Project Larrabe to datacenters with a ton of not very useful cores that are good at doing things in a way that suddenly seems like a fundamental mismatch in architecture.
-Fran-
Glorious
- May 3, 2007
- 9,557
- 3,106
- 47,640
No, he did include the accelerators:He also didn't use HBM2e or accelerators. Leaving more than a little performance on the table. It is more like a comparison of Nvidia to AMD where Nvidia turns off their cache, tensor and RTX cores.
Intel does state an average 2.9x improvement in perf/watt with the accelerators on vs the 8380 with the tests they ran. That's probably 50% more performance in general. Workloads targeted by the accelerators (4 of each):
might make Epyc look like the new Project Larrabe to datacenters with a ton of not very useful cores that are good at doing things in a way that suddenly seems like a fundamental mismatch in architecture.
"Well, it was a busy past four days of benchmarking Sapphire Rapids and only hitting the tip of the iceberg when it comes to exploring Sapphire Rapids' performance potential around AMX and the accelerators."
"To no surprise, software that is part of Intel's oneAPI collection or leveraging Intel's vast open-source software portfolio is in good shape for Sapphire Rapids and the new Max Series products."
https://www.phoronix.com/review/intel-xeon-platinum-8490h
He didn't have time to test more of them, but he did include all available ones which aren't too specific.
Also, isn't the "H" the HBM2e version?
Regards.
Read more carefully:No, he did include the accelerators:
"Well, it was a busy past four days of benchmarking Sapphire Rapids and only hitting the tip of the iceberg when it comes to exploring Sapphire Rapids' performance potential around AMX and the accelerators."
"To no surprise, software that is part of Intel's oneAPI collection or leveraging Intel's vast open-source software portfolio is in good shape for Sapphire Rapids and the new Max Series products."
https://www.phoronix.com/review/intel-xeon-platinum-8490h
He didn't have time to test more of them, but he did include all available ones which aren't too specific.
Also, isn't the "H" the HBM2e version?
Regards.
"Due to just the four day window of receiving the Sapphire Rapids hardware to embargo lift, the benchmarks today aren't focused on the accelerator side due to the short timeframe to prepare my testing for them properly in setting them up and verifying the correct operation, etc. As part of the reviewers material Intel did provide some sample accelerated benchmarks they recommend, but are not permitting the public redistribution of those assets post-launch. With my longstanding focus on transparency and reproducibility of benchmark results by any/all parties, it's hardly interesting running some vendor-provided scripts that can't be obtained by the general public for evaluating on their own hardware in calculating upgrade benefits or analyzing the software implementation. So I'll be setting up my own accelerator benchmarks from the public repositories of code already prepared for Sapphire Rapids, etc. The accelerator benchmarking will also be much more interesting over the months ahead as more real-world, open-source and upstream software begins supporting the new accelerator IP of Sapphire Rapids."
Also:
"At the moment the Intel Xeon Platinum 8490H is the only SKU of the Sapphire Rapids line-up I currently have available for review at Phoronix. Intel kindly supplied two of the Xeon Platinum 8490H processors and their reference server platform for my review and Linux benchmarking at Phoronix. Hopefully with time we'll also be able to test other SKUs, particularly the Xeon CPU Max Series with the 64GB of HBM2e memory should be very interesting considering the performance uplift we've been enjoying out of Milan-X. "
So, while Larabel is quite capable and doing a heck of a job, he doesn't have the time to write his own accelerator benching software for the as yet unreleased chips in 4 days, and manufacture his own HBM2e and put in on there, along with changing the PCB to hold them.
Also look at the top of this Tom's article, they put in photos of with HBM and without. You can clearly see Phoronix is without.
thestryker
Judicious
- Apr 19, 2016
- 5,875
- 4,059
- 36,690
While I do agree it should have been released last year for maximum impact it's not all that dire. Reading the Serve the Home initial piece on SPR indicated availability for Genoa isn't good yet whereas Intel does not have this issue.I just read the Phoronix review of SP and... Holy cow it's not good. You can tell this should've released last year. AMX does most of the heavy lifting for Intel, but who is running inference jobs on CPUs at the enterprise level anyway? And even then, it's not like AMD has bad performance for the price, considering it's not 2X the performance (over AMD), but it's almost 2X the price (not counting full rack, obviously).
Michael (from Phoronix) didn't include DB tests either, where the gap would also increase in favour of AMD for sure. So there's also that. Although that HBM2e "cache" should help a lot in DB apps. We'll see, but I think AMD may still have the advantage.
Regards.
A lot of the advantage AMD has is the 12CH memory controller, but this comes with a pretty big disadvantage and that is they're limited to 1DPC for now. This gives Intel an immediate 4 DIMM per socket advantage which is up to 1TB with DDR 5.
Then of course you also have all of the accelerators available which can have huge impact should your workload take advantage. The biggest question here is the cost to activate them on the CPUs that don't come with them enabled.
Overall it seems like AMD is the only choice for general compute as it has the wider memory bus, more cores and higher clocks. Intel is certainly carving out its use case with accelerators, higher memory capacity and lower TDP parts. I'm thinking most choices this generation are going to come down to use case and availability.
As an aside the power consumption numbers in the Phoronix might not be showing the whole story as STH saw higher power consumption at the wall with AMD. I don't know if this is down to platform or the same TDP vs PPT nonsense that AMD pulled with Zen 4 in desktop form.
Nope the HBM versions are the Max CPUs which carry the 9400 series model numbers and Intel did not sample any of these to press. I'm assuming general availability on these parts is much lower as they're the ones going into supercomputers.Also, isn't the "H" the HBM2e version?
-Fran-
Glorious
- May 3, 2007
- 9,557
- 3,106
- 47,640
Er... Just because he didn't include all potential use cases of the accelerators, it doesn't mean he didn't include any. That is what I referenced. Follow up reviews are not uncommon when there's a ton of testing, but with this partial picture, I don't like SPR. At least, not as an all-purpose server part. Accelerators aren't so simple to adopt in an ecosystem, unless they're readily available for all vendors; this being said, good Intel is at least using OSS to implement and not forcing privative software outside of Optane.Read more carefully:
"Due to just the four day window of receiving the Sapphire Rapids hardware to embargo lift, the benchmarks today aren't focused on the accelerator side due to the short timeframe to prepare my testing for them properly in setting them up and verifying the correct operation, etc. As part of the reviewers material Intel did provide some sample accelerated benchmarks they recommend, but are not permitting the public redistribution of those assets post-launch. With my longstanding focus on transparency and reproducibility of benchmark results by any/all parties, it's hardly interesting running some vendor-provided scripts that can't be obtained by the general public for evaluating on their own hardware in calculating upgrade benefits or analyzing the software implementation. So I'll be setting up my own accelerator benchmarks from the public repositories of code already prepared for Sapphire Rapids, etc. The accelerator benchmarking will also be much more interesting over the months ahead as more real-world, open-source and upstream software begins supporting the new accelerator IP of Sapphire Rapids."
Also:
"At the moment the Intel Xeon Platinum 8490H is the only SKU of the Sapphire Rapids line-up I currently have available for review at Phoronix. Intel kindly supplied two of the Xeon Platinum 8490H processors and their reference server platform for my review and Linux benchmarking at Phoronix. Hopefully with time we'll also be able to test other SKUs, particularly the Xeon CPU Max Series with the 64GB of HBM2e memory should be very interesting considering the performance uplift we've been enjoying out of Milan-X. "
So, while Larabel is quite capable and doing a heck of a job, he doesn't have the time to write his own accelerator benching software for the as yet unreleased chips in 4 days, and manufacture his own HBM2e and put in on there, along with changing the PCB to hold them.
Also look at the top of this Tom's article, they put in photos of with HBM and without. You can clearly see Phoronix is without.
The review measured socket power via RAPL (software reading of power consumption). It's fairly clear Michael says Genoa is fairly more efficient than SPR across every test, including AI tests. I'd imagine it's just the nature of the instruction support with Intel, since AMD seems to not blow its power budget using AVX512.While I do agree it should have been released last year for maximum impact it's not all that dire. Reading the Serve the Home initial piece on SPR indicated availability for Genoa isn't good yet whereas Intel does not have this issue.
A lot of the advantage AMD has is the 12CH memory controller, but this comes with a pretty big disadvantage and that is they're limited to 1DPC for now. This gives Intel an immediate 4 DIMM per socket advantage which is up to 1TB with DDR 5.
Then of course you also have all of the accelerators available which can have huge impact should your workload take advantage. The biggest question here is the cost to activate them on the CPUs that don't come with them enabled.
Overall it seems like AMD is the only choice for general compute as it has the wider memory bus, more cores and higher clocks. Intel is certainly carving out its use case with accelerators, higher memory capacity and lower TDP parts. I'm thinking most choices this generation are going to come down to use case and availability.
As an aside the power consumption numbers in the Phoronix might not be showing the whole story as STH saw higher power consumption at the wall with AMD. I don't know if this is down to platform or the same TDP vs PPT nonsense that AMD pulled with Zen 4 in desktop form.
"The Xeon Platinum 8490H in both single and dual socket configurations consumed significantly more power than the prior-generation Ice Lake CPUs and even the EPYC Genoa SKUs. Across all of the benchmarking a 303 Watt average was observed and a peak power consumption of 379 Watts, as exposed via the RAPL sysfs interfaces. Meanwhile the Xeon Platinum 8380 had a 223 Watt average and a 293 Watt peak across the set of benchmarks while the EPYC 9654 also had a 223 Watt average while at a 363 Watt peak."
Ah, so the H means "HBM-less"? That's a head scratcher...Nope the HBM versions are the Max CPUs which carry the 9400 series model numbers and Intel did not sample any of these to press. I'm assuming general availability on these parts is much lower as they're the ones going into supercomputers.
Regards.
For those that are deep into Comp Sci and professional hard core devs, Intel just released an updated version of the Optimization and S/W dev manuals. You might find them an useful intro into how to release the power of accelerators. I particular i recommend chapter 19 (FP16 instructions), chapter 20 (AMX and AI - highly recommended for Comp Sci folks who work in or study the AI field) and chapter 22 (Quick Assist). For some reason they have not updated Chapter 21 Crypto (may not be ready yet...)
It helps if you already are pretty comfortable with Intel assembly and the Intel CPU architecture.
Intel® 64 and IA-32 Architectures Optimization Reference Manual
Some of the other manuals are also updated:
Intel® 64 and IA-32 Architectures Software Developer Manuals
I spent a few hours on this so far scratching the surface, primarily on Chapter 19 (FP16) and 20 (AMX).
In my view it is pretty impressive work by Intel!
Some really deep thinking went into this! E.g. how to update your existing neural net implementations, adjust/update GEMM and other core components of matrix multiplication in neural net, connecting to Py torch etc, to get max value out of AMX with BF16. and I mean both at the conceptual level and in detail - like complete code at the assembly instruction level detail!
I'm almost sold. When these are available for the W790 platform, I'm getting a W34xx and building a new system (if i can afford one 😂)!
It helps if you already are pretty comfortable with Intel assembly and the Intel CPU architecture.
Intel® 64 and IA-32 Architectures Optimization Reference Manual
Some of the other manuals are also updated:
Intel® 64 and IA-32 Architectures Software Developer Manuals
I spent a few hours on this so far scratching the surface, primarily on Chapter 19 (FP16) and 20 (AMX).
In my view it is pretty impressive work by Intel!
Some really deep thinking went into this! E.g. how to update your existing neural net implementations, adjust/update GEMM and other core components of matrix multiplication in neural net, connecting to Py torch etc, to get max value out of AMX with BF16. and I mean both at the conceptual level and in detail - like complete code at the assembly instruction level detail!
I'm almost sold. When these are available for the W790 platform, I'm getting a W34xx and building a new system (if i can afford one 😂)!
Last edited:
all the big once. Amazon for instanceCare to provide an example, please?
Regards.
The thing is that using the GPU or a specific AI accelerator adds latency to the whole process (movement back and forth between CPU and GPU/AI accelerator) .
The point is that most of the work before and after inference has to be done on the CPU anyway (data base access, network I/O, pre processing and post processing, actions based on inference result etc) so if you can implement an efficient inference engine inside the CPU, you cut out all that GPU/CPU latency and so on.
AMX is a pretty good matrix multiplication accelerator.
Not to get too technical here, but it is possible to implement activation functions very efficiently at the back end of a CPU based (e.g. AMX) matrix multiplication with almost no latency (since since the whole tile matrix is inside the CPU), e.g. applying a ReLu, Sigmoid, Swish or SoftPlus, etc - we are talking 5-20 AVX-512 assembly instructions. After that the main program continues without any latency...
Thanks, that thousand page manual you linked had some good info on a pet interest of mine.For those that are deep into Comp Sci and professional hard core devs, Intel just released an updated version of the Optimization and S/W dev manuals. You might find them an useful intro into how to release the power of accelerators. I particular i recommend chapter 19 (FP16 instructions), chapter 20 (AMX and AI - highly recommended for Comp Sci folks who work in or study the AI field) and chapter 22 (Quick Assist). For some reason they have not updated Chapter 21 Crypto (may not be ready yet...)
It helps if you already are pretty comfortable with Intel assembly and the Intel CPU architecture.
Intel® 64 and IA-32 Architectures Optimization Reference Manual
Some of the other manuals are also updated:
Intel® 64 and IA-32 Architectures Software Developer Manuals
I spent a few hours on this so far scratching the surface, primarily on Chapter 19 (FP16) and 20 (AMX).
In my view it is pretty impressive work by Intel!
Some really deep thinking went into this! E.g. how to update your existing neural net implementations, adjust/update GEMM and other core components of matrix multiplication in neural net, connecting to Py torch etc, to get max value out of AMX with BF16. and I mean both at the conceptual level and in detail - like complete code at the assembly instruction level detail!
I'm almost sold. When these are available for the W790 platform, I'm getting a W34xx and building a new system (if i can afford one 😂)!
On the topic of Intel being generous with information and tools to better use their products, somehow I stumbled across these on a driver update search: Intel® Graphics Performance Analyzers
Anybody can just download and use them for little benefit other than entertainment if you are a layperson, but hopefully more if you are looking for more details to optimize your game for Arc. I nonchalantly played around with it for a little over an hour before I realized it wasn't going to do me any good and here are a few pics: The third is a time scale zoom in of the second to show some crazy precision. Somehow all of this event recording didn't noticeably hurt performance.
-Fran-
Glorious
- May 3, 2007
- 9,557
- 3,106
- 47,640
Not according to their own presented roadmap back in Dec 2020. They were moving away from GPUs and CPUs into their own specialized FPGAs. They still offer them, but they were transitioning back then.all the big once. Amazon for instance
The thing is that using the GPU or a specific AI accelerator adds latency to the whole process (movement back and forth between CPU and GPU/AI accelerator) .
The point is that most of the work before and after inference has to be done on the CPU anyway (data base access, network I/O, pre processing and post processing, actions based on inference result etc) so if you can implement an efficient inference engine inside the CPU, you cut out all that GPU/CPU latency and so on.
AMX is a pretty good matrix multiplication accelerator.
Not to get too technical here, but it is possible to implement activation functions very efficiently at the back end of a CPU based (e.g. AMX) matrix multiplication with almost no latency (since since the whole tile matrix is inside the CPU), e.g. applying a ReLu, Sigmoid, Swish or SoftPlus, etc - we are talking 5-20 AVX-512 assembly instructions. After that the main program continues without any latency...
"Last year, AWS launched the home-grown Inferentia inference processor, which appears to be gaining traction outside of internal applications at Amazon. Inferentia delivers excellent price/performance and latency, according to AWS—a purported 35% better throughput at a 40% lower price than GPUs. Notably, AWS did not state which GPUs it put up against Inferentia."

Amazon AWS Ramps New Hardware For AI
Analyst Karl Freund provides a recap of the AI news from AWS's re:Invent 2020 event.
 www.forbes.com
www.forbes.com
It may have changed, but I haven't found anything newer.
As for Google, I do remember they also designed their own FPGAs/Accelerators for AI related workloads. Very specialized hardware.
Regards.
Right they use both FPGA (well advertised) BUT they also use Intel Xeon's (not as well advertised) - AWS is huge and with tons of customers that runs many different AI implementations. Further, Intel take requirements from Amazon when designing their Xeons simply to keep Amazon as a big customer - inference included.Not according to their own presented roadmap back in Dec 2020. They were moving away from GPUs and CPUs into their own specialized FPGAs. They still offer them, but they were transitioning back then.
"Last year, AWS launched the home-grown Inferentia inference processor, which appears to be gaining traction outside of internal applications at Amazon. Inferentia delivers excellent price/performance and latency, according to AWS—a purported 35% better throughput at a 40% lower price than GPUs. Notably, AWS did not state which GPUs it put up against Inferentia."
Amazon AWS Ramps New Hardware For AI
Analyst Karl Freund provides a recap of the AI news from AWS's re:Invent 2020 event.
It may have changed, but I haven't found anything newer.
As for Google, I do remember they also designed their own FPGAs/Accelerators for AI related workloads. Very specialized hardware.
Regards.
Why? Similar reasons why Apple is not advertising that iCloud is actually running on Microsoft cloud infrastructure (Azure)...
- Jan 20, 2010
- 20,076
- 11,073
- 79,540



Wow, I hadn't noticed that. This is a pretty big deal. Skylake SP had regular SKUs that started around only 85 W.The Sapphire Rapids TDP envelopes span from 120W to ...
Is the increase due to PCIe 5.0? Or did Intel get too ambitious, elsewhere?
Last edited:
thestryker
Judicious
- Apr 19, 2016
- 5,875
- 4,059
- 36,690
The increase in PCIe lanes probably has more to do with increased power consumption than PCIe 5.0 though it likely has some impact. They also have 2 more memory channels which are also running a fair bit higher clock speeds. The Xeon Silver CPUs start at 150W for 10 core, but they also feature higher base/boost than SKL.Wow, I hadn't noticed that. This is a pretty big deal. Skylake SP had regular SKUs that started around only 85 W.
Is the increase due to PCIe 5.0? Or did Intel get too ambitious, elsewhere?
- Jan 20, 2010
- 20,076
- 11,073
- 79,540
Okay, but we went from OG 14 nm to Intel 7. So, that ought to cover the clock speed difference.The increase in PCIe lanes probably has more to do with increased power consumption than PCIe 5.0 though it likely has some impact. They also have 2 more memory channels which are also running a fair bit higher clock speeds. The Xeon Silver CPUs start at 150W for 10 core, but they also feature higher base/boost than SKL.
Anyway, look what I found in the Ark entry for the 4410Y (Silver):
Intel® Speed Select Technology - Performance Profile (Intel® SST-PP)
| Config | Active Cores | Base Frequency | TDP | Description |
|---|---|---|---|---|
| 4410Y(0) | 12 | 2.0 | 150 | |
| 4410Y(1) | 8 | 2.0 | 130 | |
| 4410Y(2) | 6 | 2.2 | 125 |
We can compare the 8-core configuration with that Skylake 4108, which is also 8-core and has a base frequency of 1.8 GHz. Then, we see an extra 45 W or 52.9% more power for 67% more PCIe lanes and 33% more memory channels. So, I'm not convinced that mere lane + channel counts explain the full difference.
- Jan 20, 2010
- 20,076
- 11,073
- 79,540
My take is more general: Intel is using purpose-built accelerators where they can offer better perf/W and perf/mm^2 in an almost identical strategy to the way they added E-cores to boost perf/W and perf/mm^2 (therefore, also perf/$) of Alder Lake.My take: Intel is betting on an investment in very specific accelerator silicon (as opposed to using that silicon budget to add more general cores etc) will be competitive against AMD EPYC many more core products.
The bet is that the largest investments that their customers do will be in server capacity for AI (obviously), data traffic/ encryption (also obviously) etc. etc. (read their marketing above) and not in general server performance improvements (across all work loads - even though there is some of that as well with gen 4).
Unfortunately, most of these accelerators require explicit application-level support. That comes almost for free with AMX, since Intel has patched support into the most common frameworks. In the cases of QAT and IAA, they also reference industry-standard databases and software packages which Intel has presumably been patching. However, it sounds like DSA and DLB might depend on ISV and end-user software modifications, to provide benefits. That's where this strategy diverges from the E-core approach.
BTW, is "AVX for vRAN" much more than simply extending AVX-512 to support fp16 data types? If not, it strikes me as a little weird they didn't just say that, since it has applications beyond vRAN (as the slide mentioned). BTW, vRAN = virtual Radio Access Network. I gather it's aimed at signal processing used in 5G basestations, or something like that. If correct, seems like an FPGA might be a better solution (and they own Altera, so...).
Yes, and remember this CPU was originally spec'd to launch in 2020, I think. In that environment, its AMX performance would've been more competitive.No doubt AI etc. is important but it is a relatively big and risky bet, ... They said they listened to their customers and this is what they said so...
Heh, Intel owns Habana Labs, so they pretty much win either way. They probably recognize their Datacenter GPU Max (or whatever Ponte Vecchio is called now) isn't cost-competitive for AI.It also felt like they got some of their customers to even say (in the intel's video stream today) that with the new gen4 Xeons they do not need special AI accelerators (from NVidia etc) since the new Xeons are good enough.
Agreed. As I mentioned above, some of these accelerators are supported by existing software packages people are already using. For them, the benefits will be transparent.I read about their Quick Accelerator thing and they require to modify OpenSSL (for example on crypto) libraries so it works, so it makes me raise an eyebrow already. I hope they don't create special libraries tied to the hardware and it can be made open/general, but this gives me a bad feeling already. This is IBM and Mainframes all over again =/
Last edited:
- Jan 20, 2010
- 20,076
- 11,073
- 79,540
W3400 definitely won't be priced at a consumer-friendly level! W2400 could've been, but I worry that putting it in the same socket as W3400 will simply make the platform too expensive.Forgot to say that intel mentioned, they are going to launch the workstation W790 series W2400 and W3400 chips on February 15th.
hopefully they will be priced at a level that we can build reasonable HEDTs out of them. W3400 looks great on paper, but priced wrong, it will be out of reach and Intel consumer HEDT will stay dead. sigh...
Comparing to Raptor Lake, clockspeeds will be somewhat disappointing. Anyway, that should be enough lanes and cores for most that have real needs exceeding what the desktop platforms offer, but lacking the budget for a W3400.
They did have an Ice Lake refresh of their Xeon W line. For enthusiasts, it was a snooze fest, because Ice Lake clocks so poorly.Last HEDT intel did, was the core i9 10980XE (2019) with fully enabled cores.
Last edited:
- Jan 20, 2010
- 20,076
- 11,073
- 79,540
Server CPUs tend to have bigger L2 cache blocks, which might be designed under the looser timing constraints of the clock speed targets server CPU need to support. It's also possible that AMX could've played a role, since I think each core has one of those and you don't find them in the desktop CPU cores.Why do workstation and server CPUs run slower than desktop PC CPUs?
I googled it and all I'm getting is: more cores means more heat which means server CPUs need to run slower. But that is obviously not true.
Xeon SKU 6434 has only 8 cores and max turbo is only 4.1GHz.
The 24 (8p/16e) core Intel ‘Raptor Lake’ Core i9-13900K will run 5.8GHz.
Is there any hope of a Xeon 8-core CPU running boost 5.8GHz someday?
Another factor is the interconnect fabric, although I assume it now typically operates in its own clock domain.
All hope is not lost, however. Lately, Intel has enabled overclocking on some Xeon W models, and leaked spec sheets have indicated they plan to continue this practice, on all of the retail-boxed 2400 and 3400 CPUs (plus, a special premium OEM model). Note the column labeled Unlocked, in these slides:
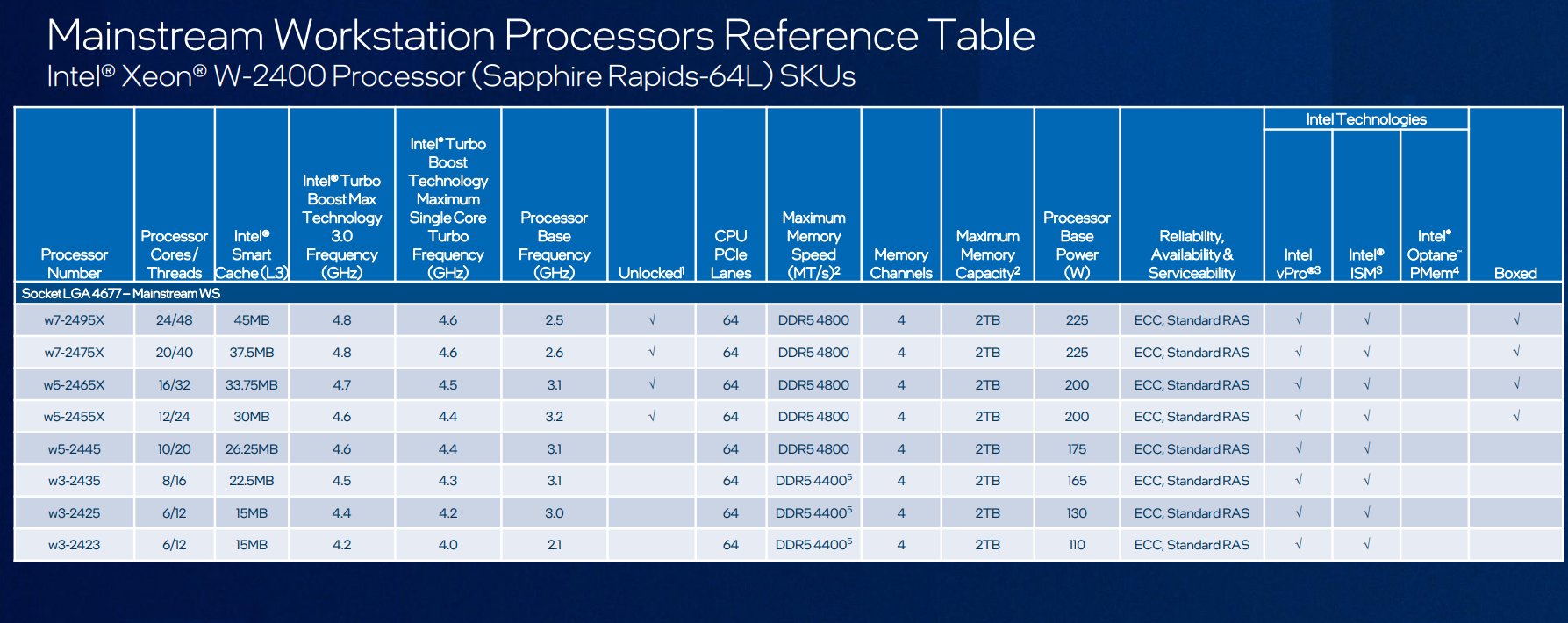
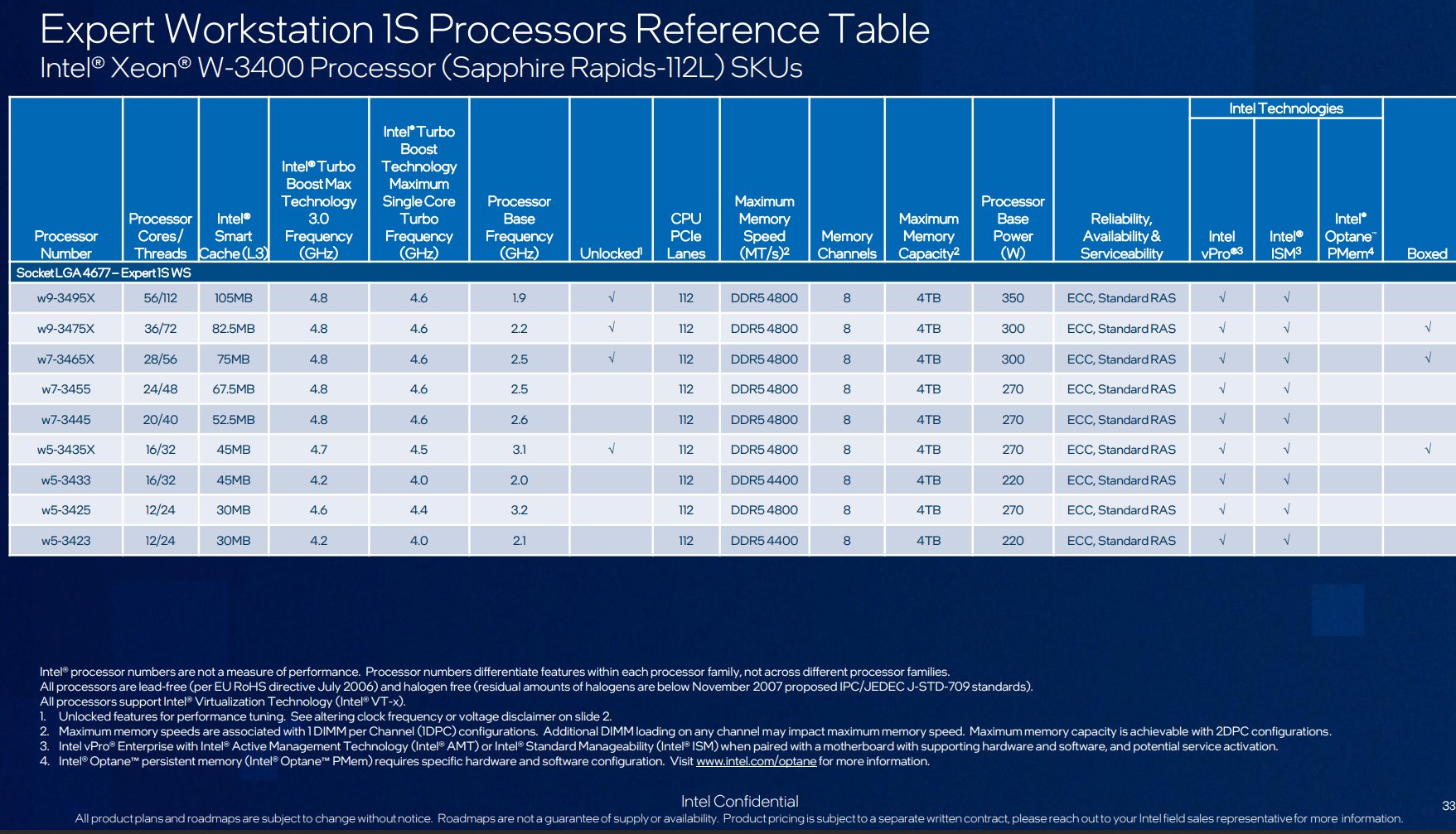
Source: https://www.tomshardware.com/news/intel-roadmap-leaks-raptor-lake-refresh-hedt-replacement-in-2023
Except market segmentation doesn't completely explain it, since these are the expensive CPUs and presumably better margins than desktop parts, yet only one model surpassed a turbo of 4.1 GHz - and even it got only to 4.2 GHz.market segmentation: Just like how consumer chips clock lower the further down the stack you go the same can be said for server/workstation chips.
The part I think you missed is that these CPUs are typically warrantied for 3 years (some, maybe more) and must support 24/7 operation at those clock speeds. More cores -> higher failure probability. So, they probably also have more margin built in than desktop CPUs.
Last edited:
TRENDING THREADS
-

-
 Question Best approach to determine what is messing with disk space
Question Best approach to determine what is messing with disk space- Started by Casualcoder0805
- Replies: 15
-

-
 Discussion What's your favourite video game you've been playing?
Discussion What's your favourite video game you've been playing?- Started by amdfangirl
- Replies: 4K
-
Question Help: Quadro K600 Driver Will Not Install on X79 Motherboard
- Started by JudithWright
- Replies: 5
Space.com is part of Future plc, an international media group and leading digital publisher. Visit our corporate site.
© Future Publishing Limited Quay House, The Ambury, Bath BA1 1UA. All rights reserved. England and Wales company registration number 2008885.
 Twitter
Twitter