General usefulness vs cost.
When you have a mainstream CPU with 64GB of on-package memory, chances are that a memory-only slot will be wasted board space and CPU pins for the vast majority of people including most power-users. May as well use those pins for extra PCIe slots that stand a much greater chance of being useful for something at some point such as extra NVMes, USB5 card or anything else that might come up in the future. If you want more RAM, you can still get a CXL memory expansion card fitted with however much of whatever DRAM type you like that someome makes a controller chip for. If you need more than 64GB of RAM and 5.0x16 is still too slow for the amount of bandwidth you need out of your 256GB DDR5 RAM expansion, it is likely fair to say you should get an HEDT/workstation/server solution, not a mainstream PC.
Or we can not try to change the current paradigm and just give you MORE DIMM slots to play with thanks to OMI and take all the extra pins as well for PCIe connections.
Win/Win, minimal changes.
With OMI, using all 4x slots on a standard consumer MoBo wouldn't tank your DIMM slot speeds due to seperate memory controllers for every pair of DIMM slots. Ergo you get the maximum Memory Speeds for each pair of DIMMs.
You get to keep your On-Package memory.
If you run out of DIMM slots, you can add in more memory via CXL.
Not everybody is going to want to spend the kind of $$$ on HEDT / WorkStation / Server solution just to have more memory. That's very Bourgeois thinking that the average person should have to spend that kind of money just to have access to more DIMM slots / memory.
Thinking that 64 GiB of on-package is "Good Enough" for you peasants who don't have the money for HEDT / WS / Server parts. We'll just take away your DIMM slots and you can have CXL in it's place. While the stupid Video Card gets so large that it's now taking 5 effing slots and blocking most of the MoBo.
The fundamental structure of DRAM chips hasn't changed since the days of FPM-DRAM: you still have row address decoder that select which memory row you want to activate, a row of sense amplifiers that detect whether the sense line of each column gets pulled high or low by the memory cell on activation to determine whether it is 0 or 1, a row of D-latches storing the sense amplifier's result, a column address mux and decoder to handle reads and writes to those D-latches and write drivers to put the new value back into cells when the memory row gets closed. The only thing that changed in a meaningful way is the external interface and even that isn't drastically different from FPM to HBM or GDDRx.
Which DRAM is cheapest at any given time is all about mass manufacturing. If direct-stacked memory was manufactured in the same volume as DDR5, it would become cheaper than DDR5 for a given capacity due to all of the extra packaging and assembly it eliminates.
All the automation, mass production, sunk costs for DDR5 on DIMMs is done, it's there.
HBM has been around for quite some time, yet the costs still haven't gone down enough that companies would consider implementing them on consumer parts after the disasterously expensive VEGA 56 / 64 / Radeon VII.
And you know that the average main stream consumer won't tolerate that level of "Profit Margins" that a Enterprise-Level memory offers.










































































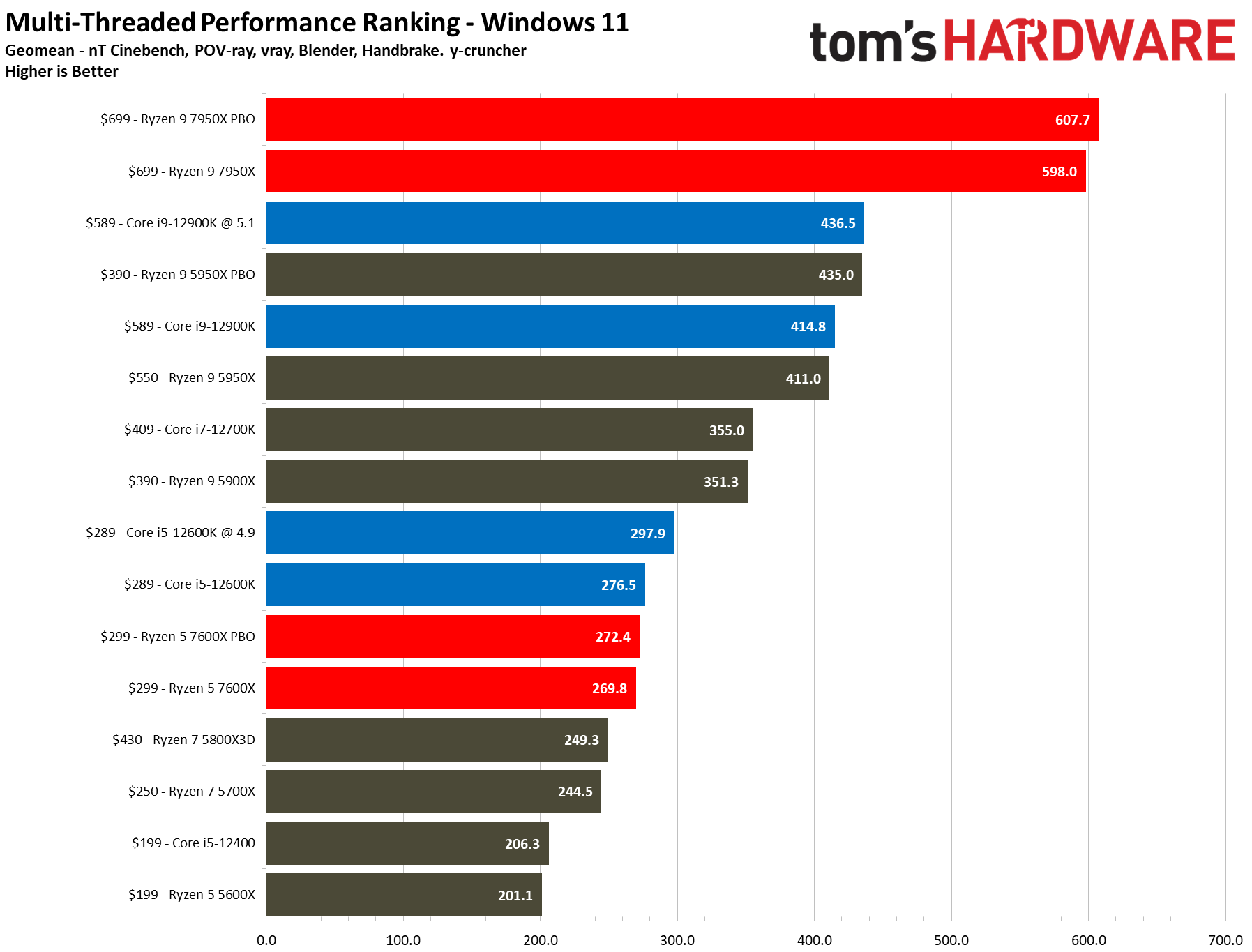
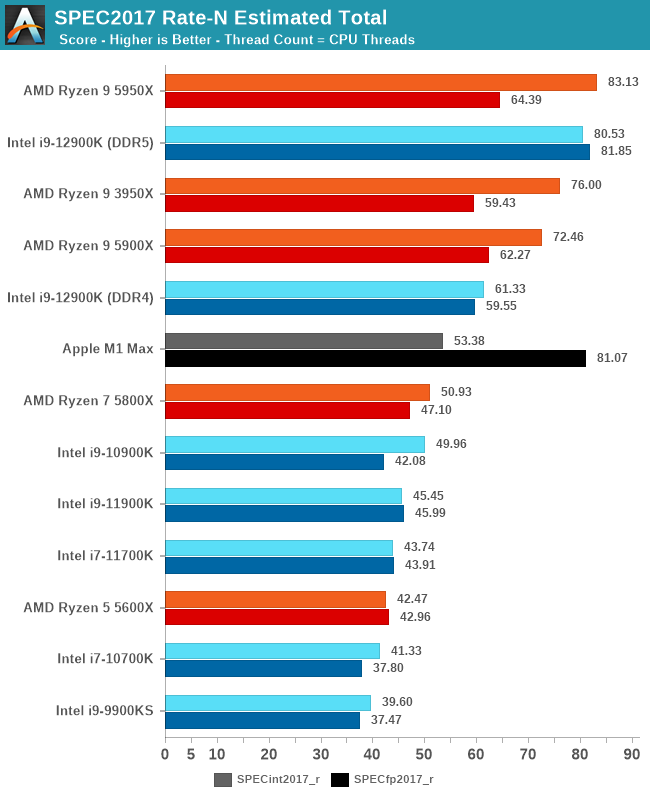

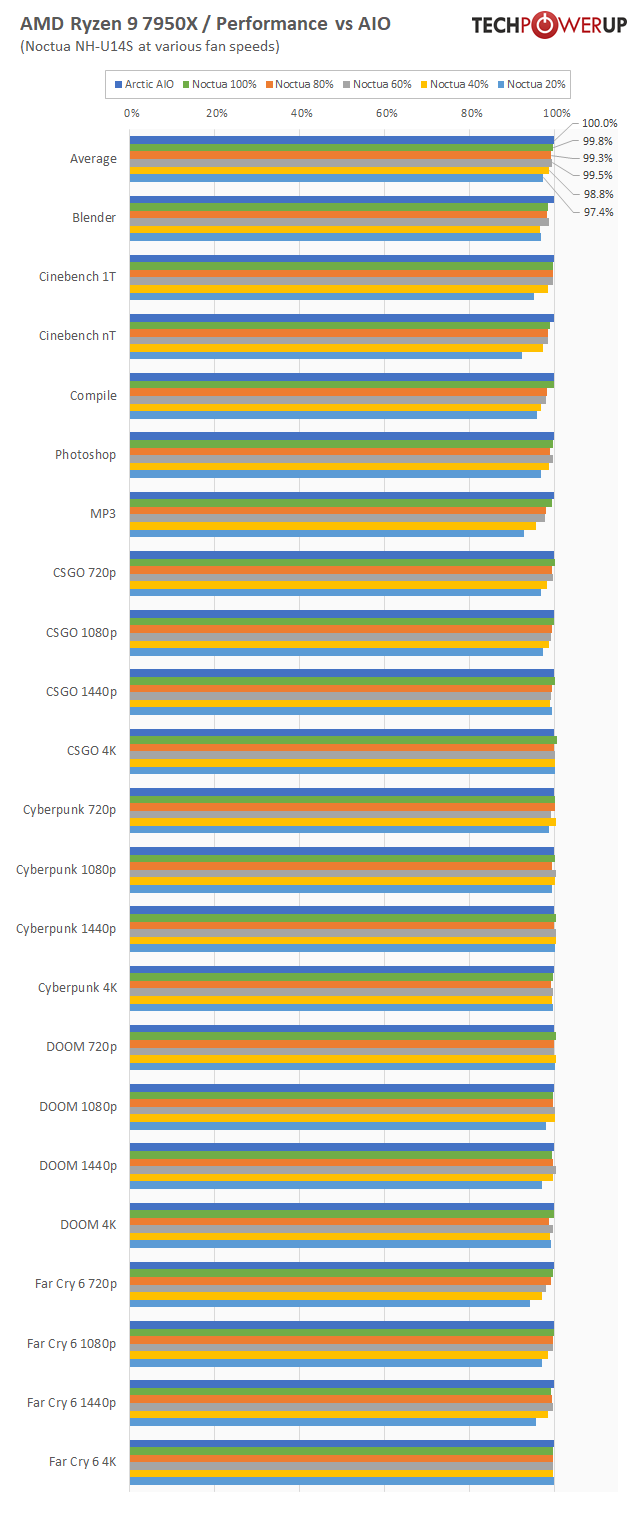

") Phoenix vs Meteorlake is the start, AMD is taking early lead with all these handheld platform wins and great reception. Is meteor lake really coming this year? 80% of success is showing up
Phoenix vs Meteorlake is the start, AMD is taking early lead with all these handheld platform wins and great reception. Is meteor lake really coming this year? 80% of success is showing up
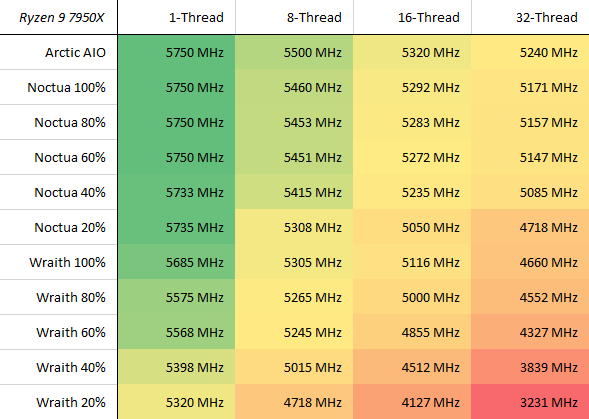
 Twitter
Twitter