SiliconFly
Commendable
- Jun 13, 2022
- 102
- 39
- 1,610







I don't think a L3 cache miss combined with a L4 cache hit will cost the tCPU close to 100 clocks. If thats the case, Intel may forego ADM L4 altogether! I'm think it's gonna be in the ballpark of X3D Vcache. A few dozen cycles at most.Before the L4$ can do its thing, the L3$ has to conclude that it missed. The read/write address also has to get to it over an off-die interface and routing fabric that connects L4$ to everything else. The L3$ adds 36 cycles on top of L2$ latency on Zen 4, a bigger L4$ made on a cheaper process (interposers are made on 12-16nm class processes if that is really where you want to put your L4$) would almost certainly add another 40+ cycles due to the much longer physical roundtrip and extra clocked hops to help cover the distance.
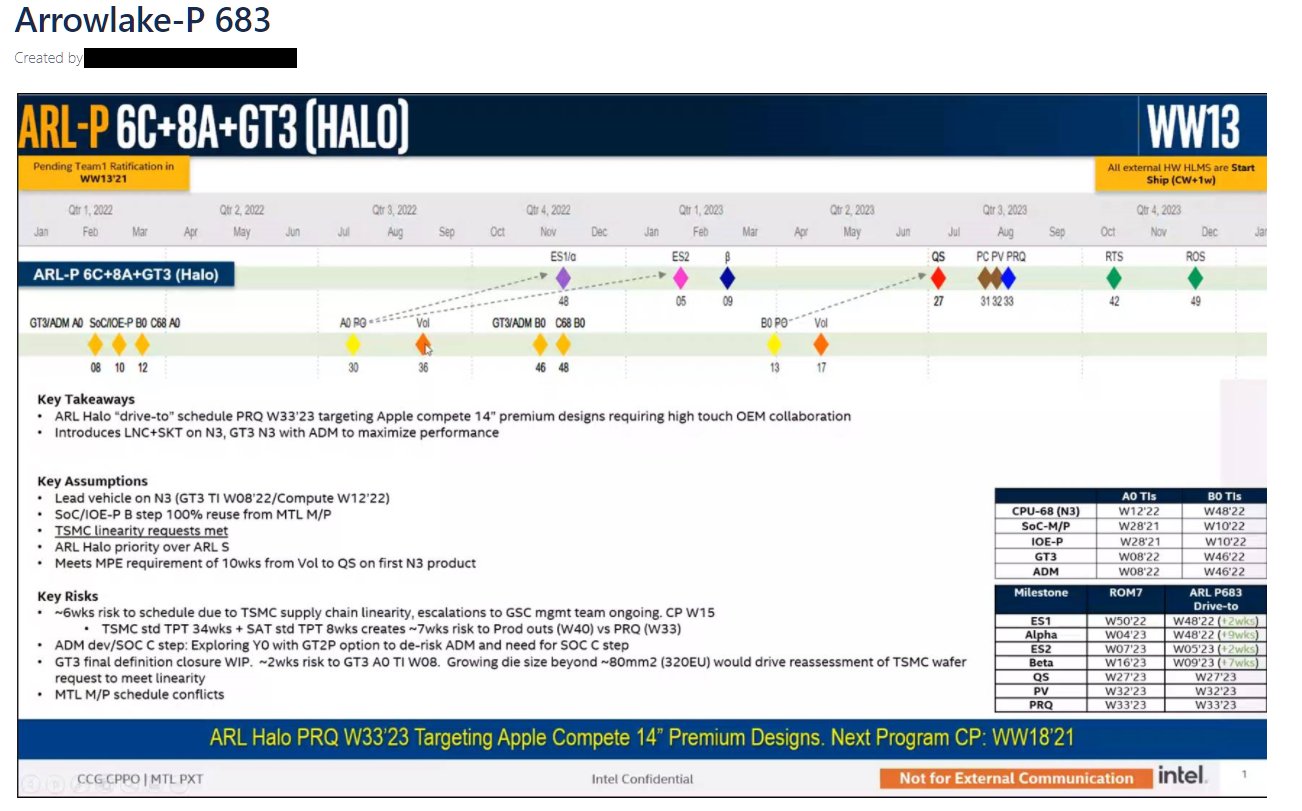
(Just a disclaimer: ADM L4 on MTL is still not confirmed)

























































 Twitter
Twitter