sarwar_r87 :
juanrga :
IPC+SMT ~ Haswell
IPC < Haswell
good to see not you comparing IPC < haswell and not ~ SB.
")
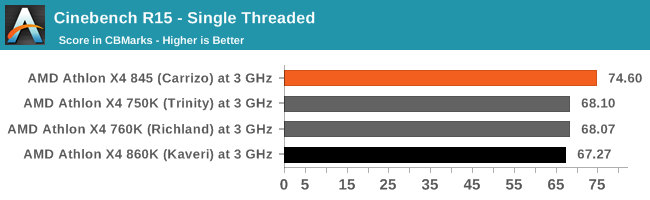
Both are compatible. If Zen is 40% above Excavator (AMD's official statement at Hot Chips), then Zen IPC is below Sandy Bridge
74.60 * 1.4 = 104.44.
But Lisa Su said at New Horizon that the original target was surpassed and that it is now "greater than 40%". I take that as something between 40% and 50%. If the IPC is 50% above Excavator, then Zen is 4% above Sandy Bridge
74.60 * 1.5 = 111.9.
The middle point, 45% over Excavator, gives exactly Sandy Bridge IPC.
That Zen IPC will be more close to Sandy than to Haswell is my
opinion, unless someone shows a CBST benchmark that demonstrates otherwise.
sarwar_r87 :
Therefore the 55% is a purely guessed number assuming that Zen has same IPC than Broadwell.
It's not a guess. its was a backward calculation based on the assumption that SMT on both platforms have the same scaling.
It is an estimation based in three asumptions: (i) Zen has about the same throughput than Broadwell, (ii) Zen has about same SMT yields than Broadwell, and (iii) the IPC gap between Broadwell and Excavator is about 55%.
sarwar_r87 :
Distributed Int Schedulers, and a higher number of statically partitioned structures are the main reasons. Intel's more dynamic approach here should result in higher ST performance, but IMO is a mistake in regards to throughput perf/watt. if not perf/mm , It makes sense to me that AMD chose to avoid such a large unified scheduler.. This is after all an architecture designed to be as balanced as possible, But given it's 2017 now (Is here in Australia!) likely biased towards throughput wherever it didn't impact ST significantly,
I saw his post before and while his reasoning is sound, there are other engineering reasons to do so:
1. power saving. as he pointed out a dynamic scheduler approach, it would will cost in terms of power requirements. and amd said their goal was power.
2. I the width of each scheduler are different, AMD has narrower with per int last time I checked. meaning they can combine two of the int to process wider data assuming without losing performance (like they do for AVX2), while running narrower width calculation using less power. in theory it translates to same ST IPC. Hence they have more ints.
3. The statement "Intel's more dynamic approach here should result in higher ST performance" assumes that there are added latencies for combining two or more ints together. there is no proof so confirm this. I, with my puny and research-oriented experience have designed systems that cascade narrow units to wider ones without any added latency. I'm sure AMD can pull it off too.
The main goal of clustering those structures is not to save power, because they aren't iddle enough time how to power off them. The main goal of clustering technique is to reduce the critical path of the circuity to allow higher clocks.
The mention of AVX2 is misguiden as well. On vector-like stuff the throughput is almost linear with the wide of the execution pipe. That is why we can combine two or more units to execute a wider vector in the same cycle. This is not what I did mean, and it is not that the author of that post mean. We are refering to the ability to extract more ILP from a sequence of instructions and execute them OoO. In this case the throughput is
not linear to the size of the window of instructions being scheduled. That is the reason why he correctly notices that an unified scheduler (like in Intel desings) has a penalty in both perf/watt and perf/mm --indeed, the penalty scales at least like O(N²)--. Distributed schedulers (like in Zen) have better perf/watt and perf/mm, but at cost of generating a less optimal schedule for a single sequence of instructions, which in the end means a lower IPC. That is the reason why he thinks that Zen will have less IPC than Haswell/Broadwell and why he thinks that AMD will have higher gains with SMT due to the more distributed nature of the muarch.
I agree with him. Of course, only a full review and detailed analysis of the Zen muarch will prove/disprove this.











































































 Twitter
Twitter