From 19th Jan to 19th Feb, CableMod does their annual production facility upgrades of their factory, affecting EU Store and Global Store,
announcement :
https://store.cablemod.com/2024-winter-shipping-notice/
This kind of testing has been done with PCI-E x16 and with GPUs.
Now, PCI-E x8 has half the bandwidth of PCI-E x16.
Same is when you compare PCI-E 4.0 to 3.0, half the speed.
For GPUs, they do not utilize the full theoretical bandwidth of PCI-E revision.
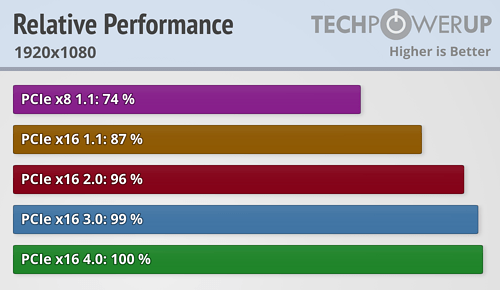
E.g RTX 3080 performance with different PCI-E revisions on 1080p resolution;
Source:
https://www.techpowerup.com/review/nvidia-geforce-rtx-3080-pci-express-scaling/27.html
RTX 3080 is PCI-E 4.0 x16 GPU, so, naturally, in PCI-E 4.0 x16, it runs at 100%.
Now, PCI-E 3.0 x16 has half the bandwidth of PCI-E 4.0 x16 and one might think the GPU performance would be 50%, but this is not so. It only drops 1%.
could be because of a bottleneck somewhere, I dont know the specifics of the benchmarking and hardware, but say you have CPU + memory + GPU creating the graphics,
eg CPU running a program from memory, progressing a 3D scenario as data in memory, and the CPU sending subprograms to the GPU via memory,
then it is highly unlikely all 3 components have exactly the right speeds the other 2 need,
the CPU will always work at top speed with the internal register data, which for 64 bit mode, are 16 special memory cells of 64 bits each, called registers or machine registers or CPU registers, which for 64 bit x86 are named rax, rbx, rcx, rdx, rsi, rdi, rbp, rsp, this set are 64 bit versions of the original 16 bit x86, and then a further 8 named r8, r9, r10, r11, r12, r13, r14, r15
16 in total,
rsp has a special function which is the stack pointer, but if you are careful you can use it for other things.
but normally you have 15 for your program, and rsp is reserved for the stack.
they had a presentation at our uni one day, where the presenter was the guy who invented subroutines! subroutines work via a memory stack.
if you write a program where the main work is with these 16 memory cells, then it will be really fast, eg say a program to count how many bits in a 64 bit number.
the x86 CPU also has other kinds of registers available eg for floating point numbers,
anyway, the next fastest speed will be memory in the L1 cache, and then the L2 cache, then the L3 cache, then uncached memory beyond all the caches.
ie there are 5 speeds for CPU data: cpu register data, L1, L2, L3, physical memory
where the programmer doesnt have control of the cache usage but the hardware manages these automagically. for the programmer the data is either in the above registers or in memory, there is no middle ground. your only control is to switch off caching. if a program tries to localise its memory processing, then it will be faster via the automagic caching. so eg if you wanted to invert the rgb pixels of non displayed image data, it will be faster to process r,g,b of pixel 1, then r,g,b of pixel 2, .....
than to process r of pixel 1, r of pixel 2, .... r of pixel 2073600=1920 x 1080, then to process g of pixel1, 2, 3, .... then process b of pixel 1, 2, 3, 4, ... of an HD image.
because if you process all 3 components of an rgb pixel, these will be consecutive bytes, and there will be less cache reloading.
now displayed images can be a different problem because these are fake memory and typically you need to disable caching for memory mapped hardware, where hardware pretends to be memory. It is probably more than 10 years since I programmed this but I think caching can be disabled per memory page via the memory management table.
anyway, the CPU isnt as fast as you think it is! its only really fast when the program is entirely in caches, and the data is entirely in the 16 cpu registers of 64 bits each.
there is also the complicating factor of speculative execution, where modern x86 will speculatively do later instructions using current data, and then discard those where the input data has changed, where it is kind of caching future action, leading to faster code.
now if the benchmark program ventures beyond all the caches, then the CPU slows down towards the memory speed.
tautologically they wouldnt use CPU caches if memory was as fast as the CPU! just the fact they use L1, L2, L3 caches, means the memory is significantly slower than the CPU, ie the memory cant keep up with the speed of the CPU, but you use the caches to mitigate, where the caches PRETEND to be the memory chip, but that pretence eventually runs out if you keep wandering further away in memory.
anyway, the physical memory is definitely slower than the CPU, and the GPU is potentially faster than the CPU but in a more specialised way. if it was slower what point in having a GPU! might as well just have another CPU as a GPU instead! thus the mere existence of GPUs means they must be faster than a CPU for their work.
so if you keep increasing the data speed between CPU and GPU, these 2 might function faster than the speed the memory can keep up with, where further increases in CPU or GPU speed are money wasted. its like having a car engine that moves the wheels so fast the tyres catch fire like a meteor! or maybe a car skidding on ice, where the ice cannot supply the traction. the engine can do 70mph, but the ice can only do 1mph. try to go faster and the wheels skid!
clever programming can mitigate eg the example above of fully processing each pixel, rather then processing red for all pixels, then green for all pixels, then blue.
also if I remember rightly pixels are arranged row by row in memory, starting at the top left, row 0 going from top left to top right, then down one pixel to row 1, going from left to right, till eventually you get to the lowest right corner.
whereas in maths, we tend to have the origin ie (0,0) at the lower left, and top right is furthest out.
PAL tv is unusual because I think it goes from left to right, then right to left, then left to right etc. but a computer image for a PAL monitor will usually be left to right only.
the advantage of PAL over NTSC is that if there is interference, PAL becomes monochrome, as the 2 opposing directions cancel out, whereas NTSC becomes garish colours leading to the nickname NTSC = "never the same colour"!
in particular it means if a program processes row0 left to right, then row1 left to right etc,
this is better use of caches than say processing row0 right to left, then row1 right to left, etc
and this is better than processing columns column0, then column1, then column2, etc.
so just doing the same processing in a different order can make a program much faster.
with HD resolution, 1 row would be 1920 x 3 = 5760 bytes. this is where cache sizes also is important, if L1 cache is 6MB, then the entire image could fit in the L1 cache and it could be a much of a muchness, but if the CPU has a 1K cache or something like that, it becomes very relevant!
but then if you have an animation of 10 seconds of 30 frames per second, where each one is HD at some 2MB, then you are talking some 600MB of memory.
or if you have 4K resolution, 3840 x 2160, that is 24883200 bytes, ie some 24MB, and that now blows the 6MB L1 cache 3 times!
note also that graphics sometimes is r,g,b,r,g,b,.... but sometimes it is done as consecutive 32 bits per pixel, where 24 are for the colours, and the remaining 8 are "alpha channel" used eg for transparency effects for overlaid images, and overlaying could be done by hardware, where eg the top byte says which overlaying it is, where potentially you could overlay 256 images.
when I programmed graphics via VESA, the system supplies lots of different graphics modes, and you then choose one, ie these scenarios are different user options. but it is so long ago I forget the precise ones available for my 2010 mobo. each PC potentially has different options.
the Amiga 500 used interleaved bitmaps, where the image was stored as planes of bits, but this MO is now obsolete, and 3rd party hardware firms created byte per component graphics. The Amiga CD console went for byte per pixel which is very fast graphics, with just 256 colours. I think the Acorn Archimedes computer which used the original ARM chip had 256 colour graphics.
the advantage of 32 bits per pixel, is you can read the pixel in one machine instruction, as one 32 bit read. whereas with r,g,b,r,g,b, the pixels are in 24 bit blocks of 3 bytes, which sometimes will cross 32 bit boundaries. advantage is less caching needed.
anyway, with that benchmarking, my money is that the bottleneck might be the physical memory. but you'd have to dissect the programs actions and collate this with how the hardware is arranged, in particular the memory, cpu, gpu and buses.
I havent actually studied the x86 buses, but just understand the concept. you can program without knowing these things, but if you know them you could write a faster program.
with graphics programming, clever programmers will design the game around the hardware limitations, and eg if you know the sizes of the caches, you might adapt the resolution to fit entire images in say the L1 cache. a game might force you to be stuck in one zone, then when you progress from that, it is one way, where it could precompute that progression whilst you were stuck in the zone.
in all cases, reducing resolution should greatly speed up graphics. eg HD graphics could be 12x as fast as 4K. 24MB per frame versus 2MB.
This PCI-E revision scaling test has also been done with the best GPU currently out there, RTX 4090,
link:
https://www.techpowerup.com/review/nvidia-geforce-rtx-4090-pci-express-scaling/28.html
So, PCI-E lane splitting, for GPUs, doesn't affect their performance in any meaningful way. Hence why MoBo makers make their MoBos like so.
do you have the info on the memory speeds?
the existence of L1, L2, L3 caches must mean memory is a lot slower than the CPU.
I dont know also if you know the speeds of L1, L2 and L3 cache memory?
would of course depend on the CPU, but maybe for say the AMD cpu requested earlier.
I imagine the GPU might have special onboard memory, but the data on this memory might need to be shunted from normal memory initially, and that might need to be read in from disk, and maybe processed also.
with the Amiga, it had a kind of 2D GPU called the blitter, which was optimised for rectangular graphics ops. blit = "block image transfer".
but when David Braben wrote the 3D game called Virus, he didnt use the blitter because he said the timecost of setting up the blitter was more than the time saving of using it, so he just did all graphics using the CPU, and it was the only realtime 3D graphics I saw on an Amiga 500, which had an approx 7MHz Motorola 68000 CPU. He wrote that originally as the flagship game for the Acorn Archimedes, where everyone said wow! but eventually he ported it to the Amiga 500 and I think Atari ST where it was just as impressive! An example of clever programming masquerading as fast hardware!
to use the blitter, you had to point its registers at the memory in question, and set up various config registers, I think these were set up via "fake memory", ie the phenomenon of memory mapped hardware, where certain zones of physical memory in fact arent memory at all but are commands for hardware listening to the memory bus.
I have the hardware manuals giving the specifics, but I'd have to spend an afternoon deciphering it!
I don't know any benchmark software that would test all drives at once, in parallel. However, you can run multiple instances of benchmark software, select different drive for each instance and start them all at quick succession. Since benchmarking a drive takes some time, you can create a situation where all drives are fully utilized at once.
Once such great tool is CrystalDiskMark, that i personally am using too;
link:
https://crystalmark.info/en/download/
On that site, there is also CrystalDiskInfo, which is superb software to check the health of your drives. I have and use that too.
Not many USB4 devices currently around, but here's further reading,
link:
https://bytexd.com/hardware/usb4-hardware-components-with-usb4-in-2023/
Source:
https://www.tomshardware.com/news/usb-4-faq,38766.html
ok, I had a read of both. it says USB4 could be 20Gbits/s, you'd have to verify a specific USB4 was 40Gbits/second.
the 2nd article talks of the naming, where they are now going for speed based names,
in maths, skilful naming is very important. change the naming scheme and things can become much better. maths people will spend a lot of time trying to decide what is a good naming system, and people have devised ingenious naming schemes. eg bra and ket for ( and ).
with the english language also, some usages of words are much better than others. for written english for confusing matters, I will try to use better wording.
the most important attribute of a bus is its speed! so this has to be the best naming MO to name involving the speed.
if you did a new version of IDE which did 40 Gbits/second, then potentially you can create an adaptor to rejig that as a USB4 socket of 40 Gbits/second.
I find it amusing that USB4 is now moving to daisychaining devices, that is how SCSI did things, and I remember a shop assistant saying SCSI has been superceded by USB where its not via daisychaining. things have gone full circle.
the amiga external floppy drives also were daisy chained, where each connected to the next one.
eg I remember in 1976 a guy in my class having a red led digital watch, I think by Timex. then move to 1978 or 1979 and liquid crystal watches superceded led ones. then fast forward towards the 2000s, and TFT screens emerge, and I think then they had lcd screens, and today we are back to led screens! and some watches have led screens, where light emitting diodes have superceded liquid crystal diodes.
Bandwidth (speed) wise, 2x USB 3.2 Gen 2x2 (20 Gbit/s) = 1x USB4 (40 Gbit/s).
MSI Ace has two rear ports of USB 3.2 Gen 2x2, type-C. Now, if you'd have Y-splitter, where on one end, there is USB4 and it splits into two USB 3.2 Gen 2x2 ports, that you can plug into MoBo, you could, theoretically, get 40 Gbit/s speeds from that one Y-splitter cable.
Another option is to use PCI-E to USB4 expansion card. E.g MSI USB4 PD100W Expansion Card (MS-4489),
specs:
https://www.msi.com/PC-Component/USB4-PD100W-EXPANSION-CARD
With this one, you could get 2x USB4 ports and 2x DP input ports.
that is then an argument to get the Ace, because if USB4 starts to become mainstream, I can use it via that adapter. I would buy that if and when it becomes necessary, not for the initial system.
5.25" external bay is
the most versatile bay when it comes to the PCs, since you can put a plethora of different devices into it, and not just ODD.
E.g i've used 5.25" external bays for: ODD, fan controller and card reader (since card reader is 3.5", i had to use 5.25" to 3.5" adapter frame).
Front I/O panels of my PCs:
I'm one of the few who sees great value in external bays, be it 5.25" or 3.5". Sadly, most people think the 5.25" external bay is only for ODD and since almost no-one isn't using ODDs anymore,
I use plenty of optical disks, namely BD-R, as BD-RW is too expensive. I think 25Gig BD-R is something like 20 pence a disk. where 1 TB of data costs maybe £8, that is seriously cheap data storage. you need to get some bluray writing software, I use some by Roxio which is good, and allows you to edit videos.
if you have a ton of archived data, which you are unlikely to use, but dont want to discard, eg dashcam footage of long journeys, BD-R's are a very cheap way to archive that data.
if you put dashcam footage on BD-Rs, bluray players will then play those vids directly from the BD-R!
PC case manufacturers aren't including the 5.25" external bays with their PC cases anymore. Some PC cases still have 5.25" external bays but those are becoming rare.
Sure.
Amazon UK:
https://www.amazon.co.uk/ASHATA-Computer-Lossless-Transmission-Typewriter-default/dp/B07PVRQZMH/
ok, that is on my shopping list for my old computer!
It needs supplementary SATA power and needs one 5.25" external bay.
Also, do note that one 9-pin internal USB 2.0 header can fully support 2x USB 2.0 headers at max bandwidth. So, when you plug all 7 devices in at the same time and use them all at once, you'd loose out on bandwidth.
that maybe explains some of the USB speed problems I get with the mobo USB panel.
Of course, another question is, IF the USB 2.0 devices you use, even fully utilize USB 2.0 bandwidth or not. If they don't, and utilize ~50% of max bandwidth, then you can comfortably use 4x such USB 2.0 devices at once.
Still, this 7 port hub can be used just fine, when all ports are populated. Just don't use all 7x devices at once. Best to use two at the time, while keeping the cables plugged in.
the problem is when the wireless USB goes too slow, which depends on which sockets I use, its possible the hub prioritises some sockets over others.
If you know how to solder well and have spare parts, you can replace the ports on MoBo.
But if you don't know how to do it, send it to Northridge Fix.

Link:
https://northridgefix.com/
could be useful!
They are USA based, but do repairs internationally. They also have Youtube channel where Alex shows the repairs he has done, and people have sent their hardware in as far places as from India or even Australia,
youtube:
https://www.youtube.com/@NorthridgeFix
Quite interesting to watch. I've watched several videos and have learned quite a lot in terms of electronics repair. Though, i don't know how to solder, still, interesting to learn something new.
")
I have a defunct calculator from 1977, which maybe they can repair!






























































 It's getting to complex to write it down, so take a look of this image instead, that i made, for clarification;
It's getting to complex to write it down, so take a look of this image instead, that i made, for clarification;













 Twitter
Twitter