













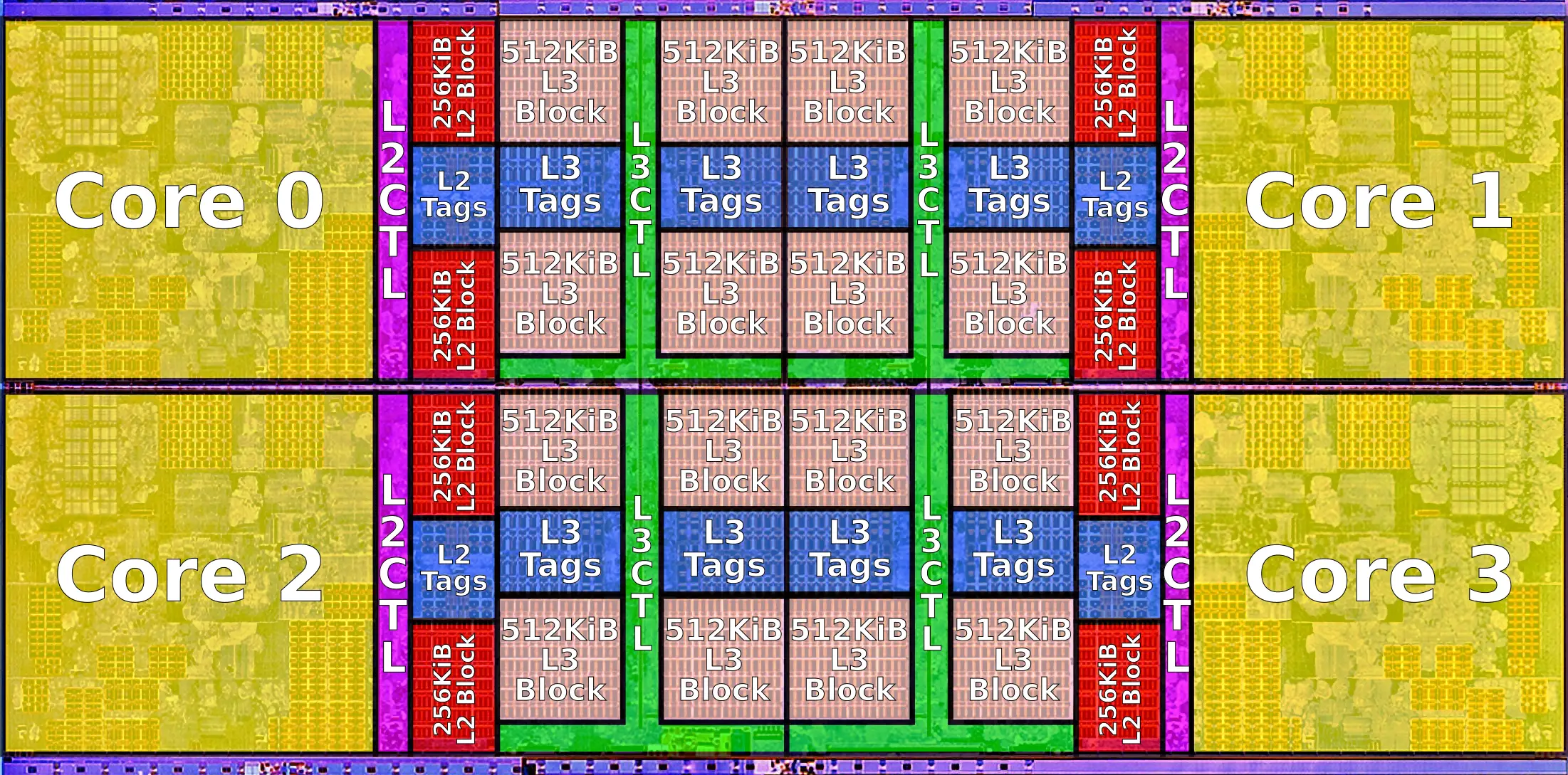
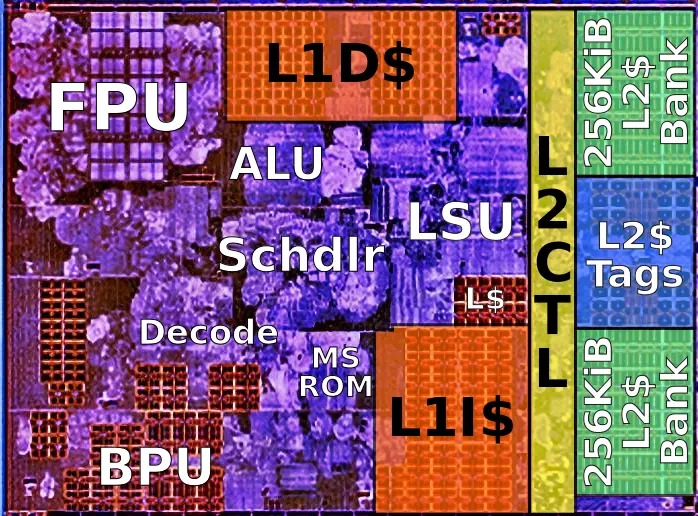
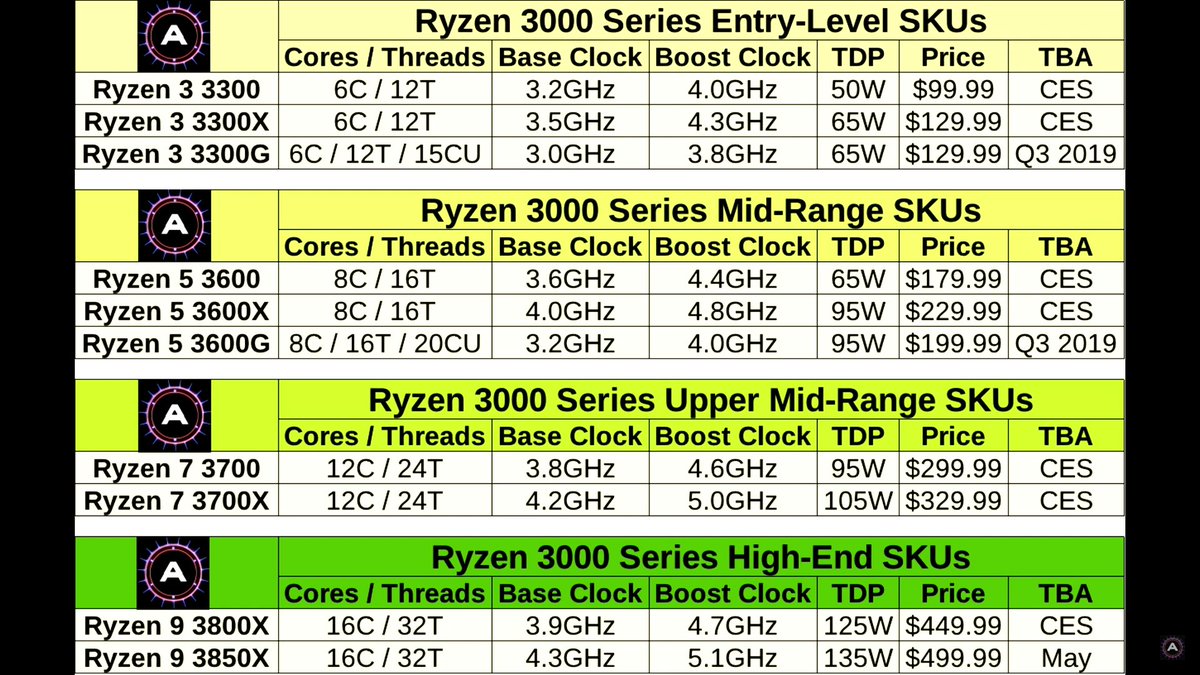
While reading top 500 news i stumbled on a couple sentences that when taken together make me think we are gonna see several AMD Rome systems in the future top500 lists.
Sources:
https://www.top500.org/news/amd-takes-aim-at-performance-leadership-with-next-generation-epyc-processor/
https://www.top500.org/news/intel-steers-back-to-hpc-with-cascade-lake-ap-processor/
Intel’s claims on Cascade Lake AP’s performance:1.21x higher Linpack performance compared to the 28-core Xeon 8180 (“Skylake”) processor
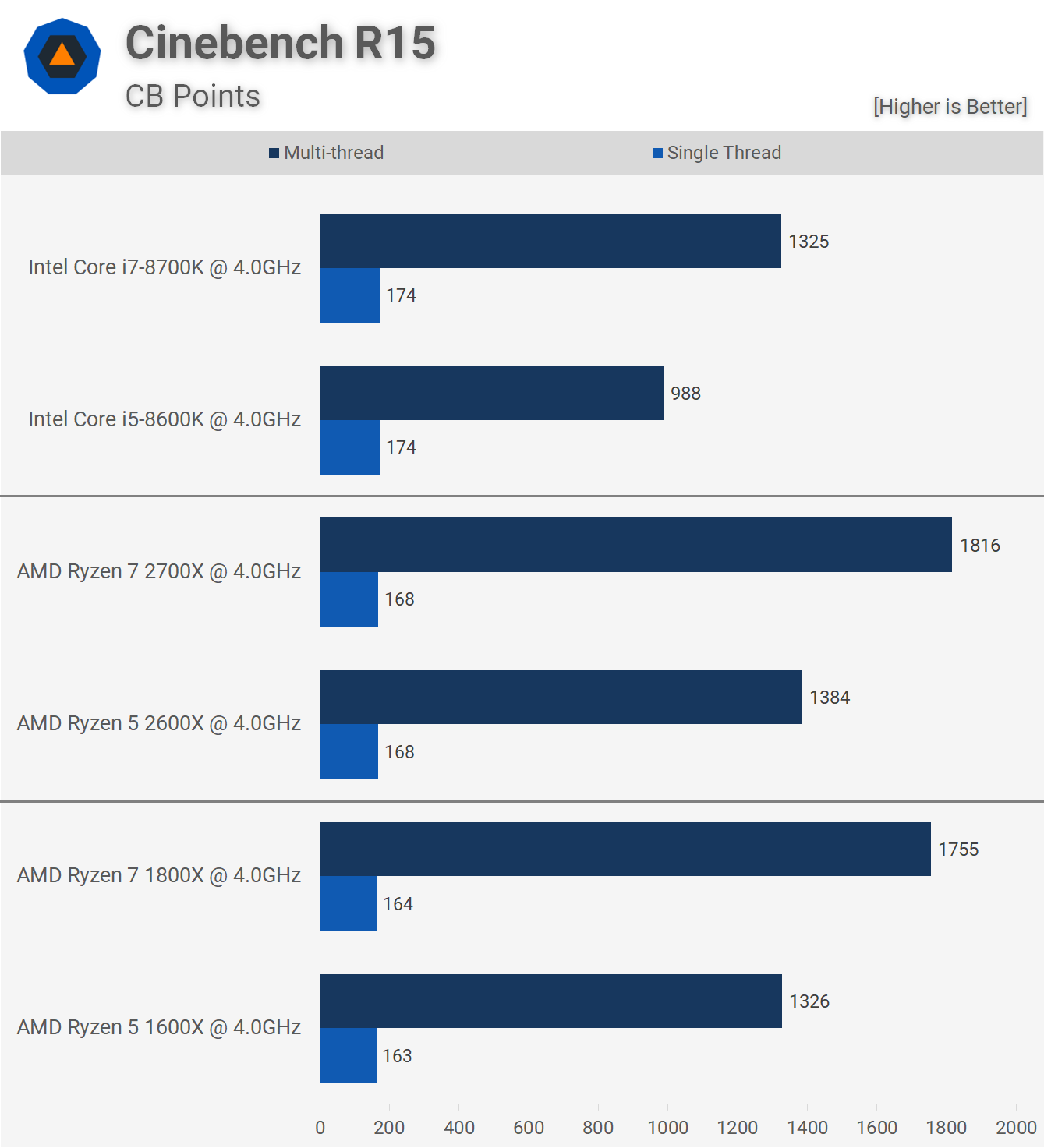
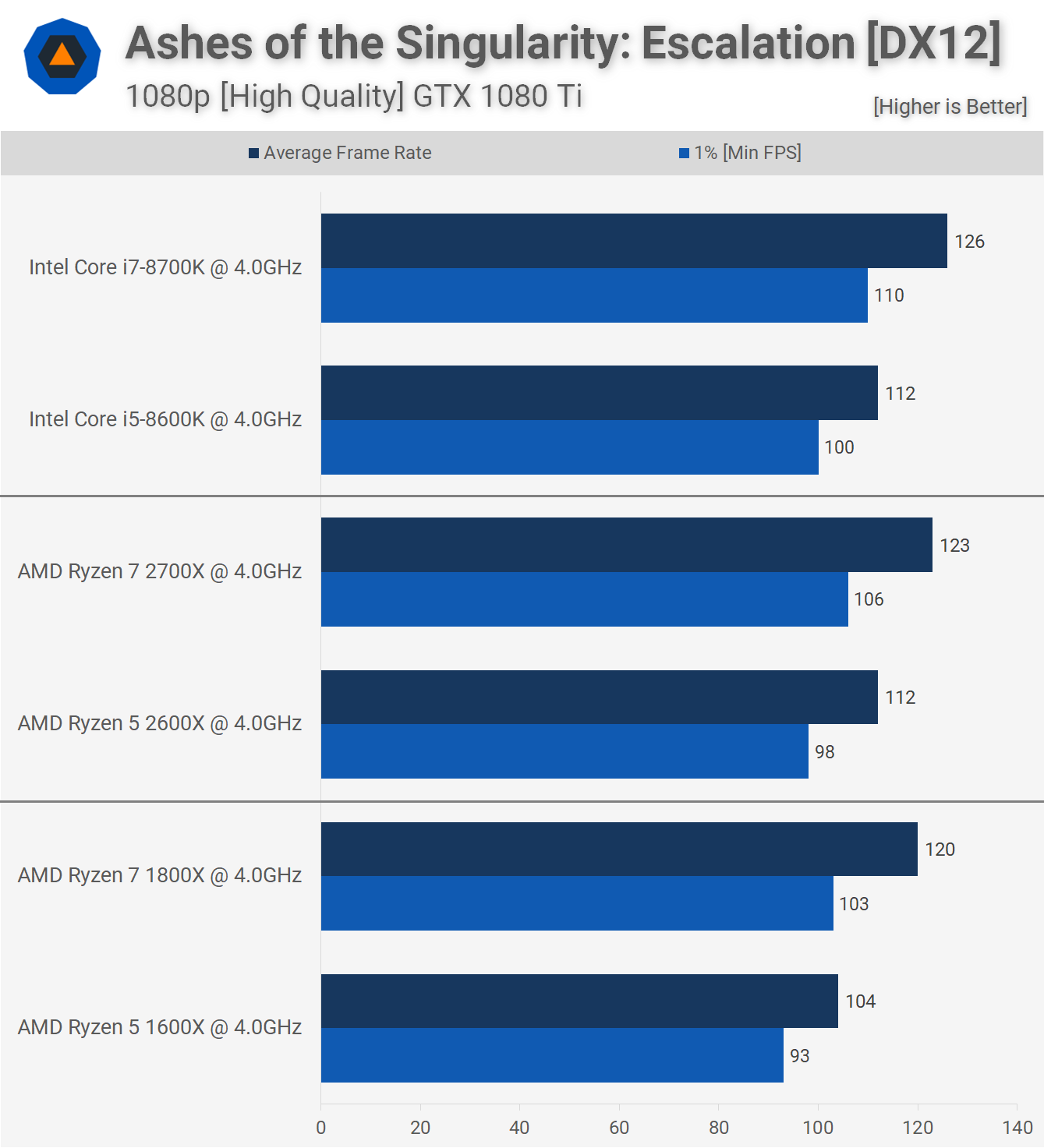
Although C-Ray is not linpack, it gives an idea of the upcoming Rome performance.To highlight the chip’s floating point performance, AMD ran the standard C-Ray rendering benchmark on-stage at the event, using a single-socket server outfitted with a pre-production version of Rome. When matched against a dual-socket Xeon Platinum 8180M server, the AMD box ran the benchmark to completion first.
Sources:
https://www.top500.org/news/amd-takes-aim-at-performance-leadership-with-next-generation-epyc-processor/
https://www.top500.org/news/intel-steers-back-to-hpc-with-cascade-lake-ap-processor/















































 Twitter
Twitter