- Jan 1, 2018
- 18,589
- 3,985
- 81,540
























I see your point, they COULD add more cores in that space.
However they would have to slow the speed down making it un competitive with 3rd gen ryzen.
As we saw with the 9900k, intels already pushing that architecture to its limits. The cpu draws soo much power and gets soo hot, adding more cores would only worsen this.
However they would have to slow the speed down making it un competitive with 3rd gen ryzen.
As we saw with the 9900k, intels already pushing that architecture to its limits. The cpu draws soo much power and gets soo hot, adding more cores would only worsen this.



















































")
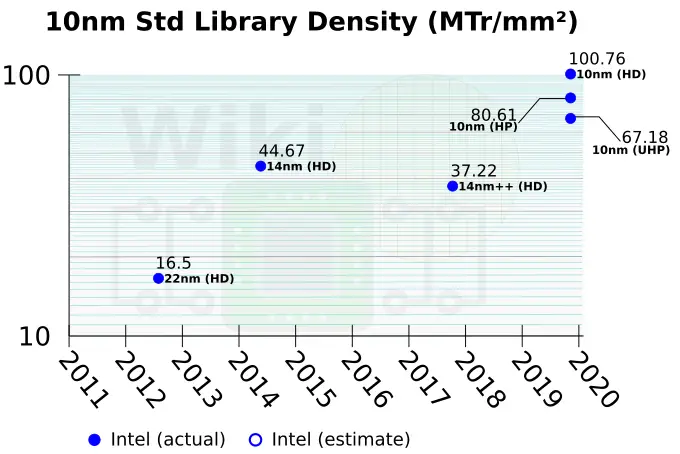
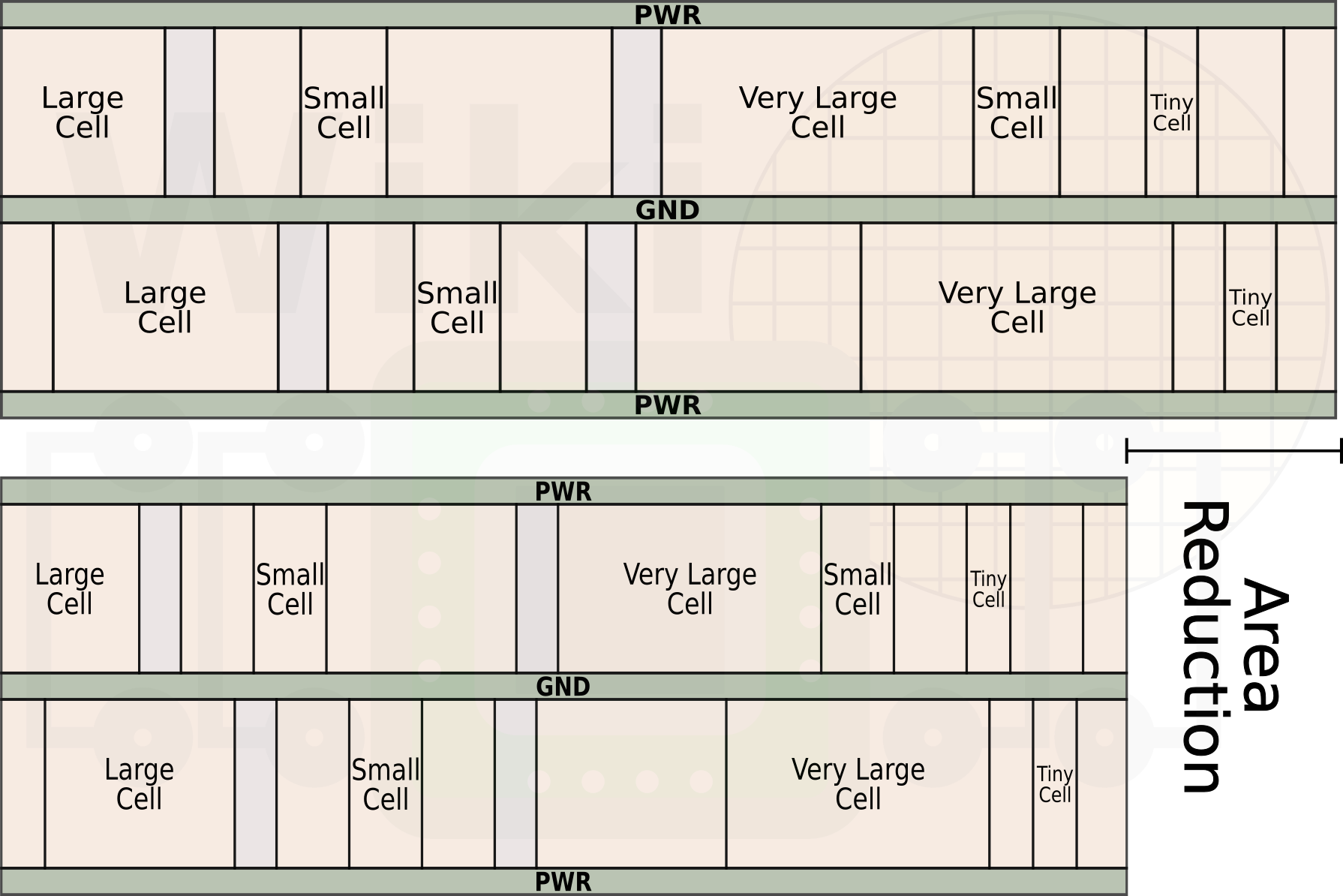






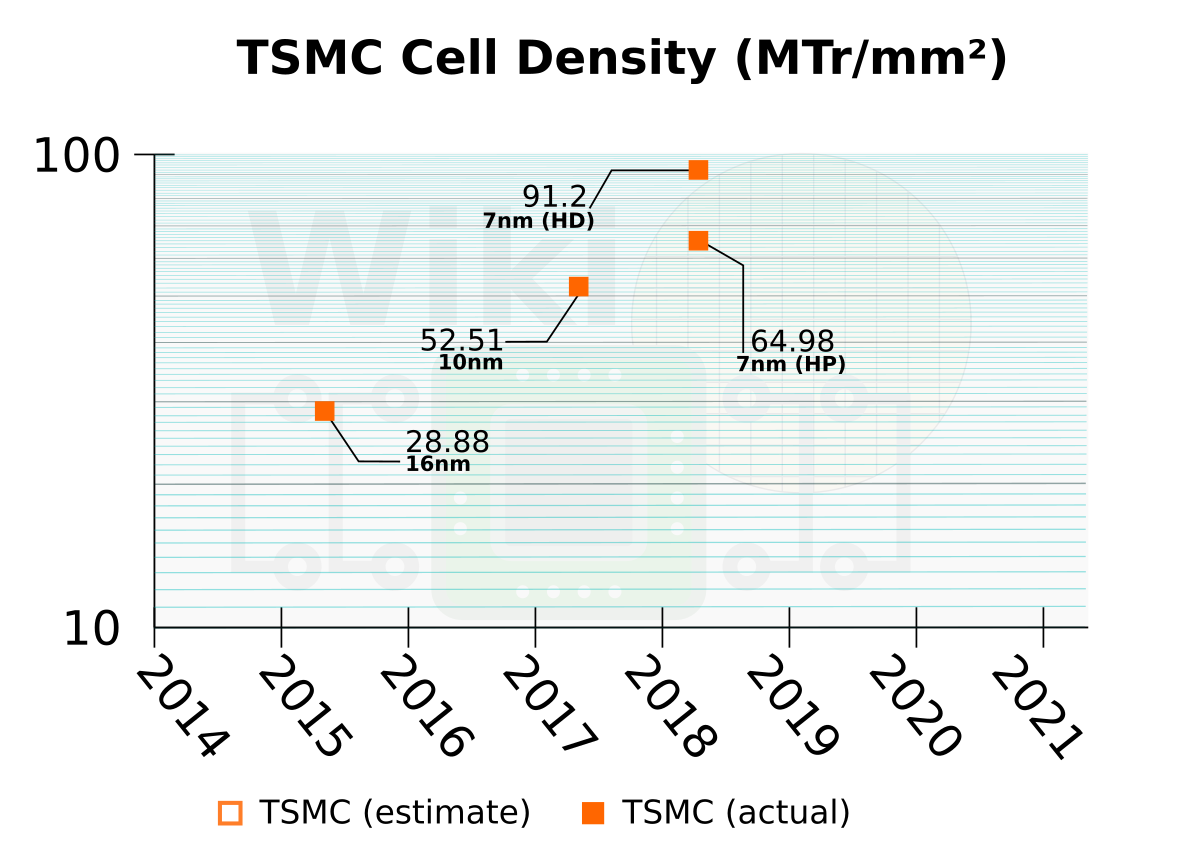
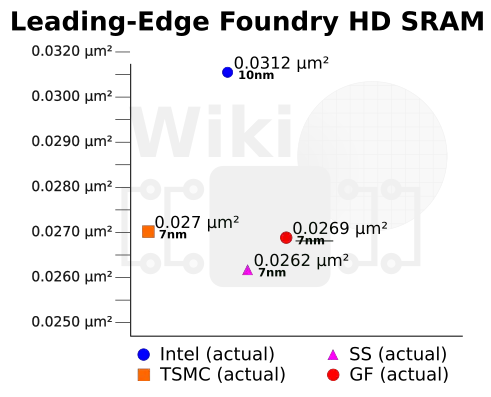
 Twitter
Twitter