News The Zen 5 Gaming postmortem: Larger generational gains than many reported, game-boosting Windows Update tested, Ryzen 5 7600X3D gaming benchmarks, too
Page 2 - Seeking answers? Join the Tom's Hardware community: where nearly two million members share solutions and discuss the latest tech.
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
- Feb 24, 2015
- 890
- 431
- 19,360
















You might want to go look at TPU's overall results for 1080p again.What am I missing? The chart shows a 6.5% performance increase between 7700x and 9700x. How is this larger than others have reported? Looks very similar to TPU results.
JarredWaltonGPU
Splendid
- Feb 21, 2020
- 2,893
- 4,708
- 23,570









Horse poop. Intel and AMD usually provide a kit of hardware, which varies depending on what's being launched. A new CPU socket will typically come with the CPU(s), motherboard, and often even memory. A new CPU for an existing socket (i.e. the Raptor Lake Refresh) will come with just the CPUs, though sometimes a motherboard vendor will send along an updated board with a "new" chipset.Intel sends them a tray CPU and a “reviewer’s guide” explaining that if they paint Intel in a negative light there will be no more samples. That’s the review kit. There’s no RAM involved. Most reviews just test Intel with faster RAM so they don’t lose their review sample permission.
There is, 100%, never language in any of the reviewer guides I've seen hinting at or stating that negative press will result in your site being cut off. Now, it I'm not saying it couldn't happen, particularly if a site continually ends up on the extreme negative outlier side of the equation... or if you're perennially late to post reviews (or just don't post them at all).
All the companies really expect is a fair shake, and they know as well as anyone when they bork a new product. Intel hasn't been doing so hot lately (see: Raptor Lake Refresh and all the failing RPL chips, plus being late with the last several process node transitions). But if you don't factor in the RPL failures, the 13th and 14th Gen chips are still quite fast, particularly for gaming. Efficient? No. Reliable? Nope. Can they definitively beat AMD's 7000-series X3D parts in games? No as well.
X3D is the only thing that consistently beats Intel in gaming perf, and even then... well, if you're worried about gaming performance, start with the GPU first.
")
https://www.tomshardware.com/pc-components/gpus/cpu-vs-gpu-upgrade-benchmarks-testing
I checked their 720p numbers, looks very similar to yours.You might want to go look at TPU's overall results for 1080p again.
JarredWaltonGPU
Splendid
- Feb 21, 2020
- 2,893
- 4,708
- 23,570
720p is not inherently the same as 1080p, FWIW.I checked their 720p numbers, looks very similar to yours.
Depends. If the areas / games / settings you are using are fully cpu bound at 1080p then it shouldn't make a difference whether it's 720p or 1080p.720p is not inherently the same as 1080p, FWIW.
TPUs results between the 7700x vs 9700x are closer together at 1080p because they are GPU bottlenecked to an extent, that's why the 9700x is also closer to the 7800x 3d than it is at 720p.
- Feb 24, 2015
- 890
- 431
- 19,360
Apples and oranges, in this case.Depends. If the areas / games / settings you are using are fully cpu bound at 1080p then it shouldn't make a difference whether it's 720p or 1080p.
TPUs results between the 7700x vs 9700x are closer together at 1080p because they are GPU bottlenecked to an extent, that's why the 9700x is also closer to the 7800x 3d than it is at 720p.
MXM0
Prominent
- Jan 14, 2024
- 20
- 12
- 515
Why aren't there revised benchmarks with Intel chips, after the OS update? I suspect any job scheduling fix probably wasn't AMD-specific, as AMD's chips are not the oddball, like they were back in the Bulldozer days, with the shared FPUs and weird modules and awful cache ping ponging.
JarredWaltonGPU
Splendid
- Feb 21, 2020
- 2,893
- 4,708
- 23,570
https://www.tomshardware.com/pc-com...indows-23h2-update-prepare-for-disappointmentWhy aren't there revised benchmarks with Intel chips, after the OS update? I suspect any job scheduling fix probably wasn't AMD-specific, as AMD's chips are not the oddball, like they were back in the Bulldozer days, with the shared FPUs and weird modules and awful cache ping ponging.
Guardians Bane
Proper
- May 28, 2024
- 143
- 82
- 160
Exactly ... I'd say the same. I'm just waiting for prices to come down more for now.
To be fair though, IMO for gaming cache is king, so RPL champs ADL for a considerable margin and X3D just hands down win.All the companies really expect is a fair shake, and they know as well as anyone when they bork a new product. Intel hasn't been doing so hot lately (see: Raptor Lake Refresh and all the failing RPL chips, plus being late with the last several process node transitions). But if you don't factor in the RPL failures, the 13th and 14th Gen chips are still quite fast, particularly for gaming. Efficient? No. Reliable? Nope. Can they definitively beat AMD's 7000-series X3D parts in games? No as well.
X3D is the only thing that consistently beats Intel in gaming perf, and even then... well, if you're worried about gaming performance, start with the GPU first.
https://www.tomshardware.com/pc-components/gpus/cpu-vs-gpu-upgrade-benchmarks-testing
For prodcutivity, 13th and 14th gen if we ignore the reliability and efficiency can still be very competitive, if it wasn't the degradation issue they can likely be good enough for 2-3 gen more GPU upgrade cycle and not really bottlenecking at meaningful FPS range
stuff and nonesense
Honorable
- Mar 10, 2020
- 760
- 535
- 11,790

Zen 5 running Star Citizen is more than fine.Exactly ... I'd say the same. I'm just waiting for prices to come down more for now.
D
Deleted member 2986452
Guest
Zen 5 running Star Citizen is more than fine.
Never heard of it... but thanks for the tip. Will check it out.
- Jan 20, 2010
- 20,147
- 11,133
- 79,540







I count Meteor Lake as a debacle, as well. Not only did it make their Raptor Lake problems that much worse by resulting in another whole generation of CPUs with warranty liabilities reaching customers hands (i.e. because Meteor Lake-S got cancelled), but even as a laptop SoC its only real bright spot is improving efficiency and battery life under light-duty workloads. For me, one of the main takeaways from the Lunar Lake launch material is just how bad Meteor Lake looks, by comparison. I was getting Ice Lake deja vu, all around.Intel hasn't been doing so hot lately (see: Raptor Lake Refresh and all the failing RPL chips, plus being late with the last several process node transitions).
The worst thing about Meteor Lake might be the lack of trust, if you listened to Intel talk it up before everything started to go south on that launch. It contributes to the sense I have of not knowing whether to believe anything else Intel is telling us.
- Jul 26, 2008
- 4,570
- 1,180
- 24,840



To be fair though, IMO for gaming cache is king, so RPL champs ADL for a considerable margin and X3D just hands down win.
For prodcutivity, 13th and 14th gen if we ignore the reliability and efficiency can still be very competitive, if it wasn't the degradation issue they can likely be good enough for 2-3 gen more GPU upgrade cycle and not really bottlenecking at meaningful FPS range
It's a bit more complicated then that, remember cache servers as a buffer between the CPU and the memory subsystem. L1 is the fastest and is where the CPU will execute from and if what it's looking for is not there then it looks in slower L2, then much slower L3 and finally catastrophe of going to system memory while everything waits. This makes things like branch prediction and prefetching more important and historically Intel has always had a better algorithm. Since todays games have such large datasets, AMD's just brute forced it by making a large L3 cache and then cramming as much as possible. That is why those X3D CPUs perform so damn well in games but need special attention to prevent games running on the wrong CCD.
- Jan 20, 2010
- 20,147
- 11,133
- 79,540
Even the best branch prediction and prefetching won't help in a memory-intensive workload, where there's simply not enough bandwidth to keep the cores fed. Assuming at least some of the data has a significant amount of reuse, increasing cache sizes would also help such cases.It's a bit more complicated then that, remember cache servers as a buffer between the CPU and the memory subsystem. L1 is the fastest and is where the CPU will execute from and if what it's looking for is not there then it looks in slower L2, then much slower L3 and finally catastrophe of going to system memory while everything waits. This makes things like branch prediction and prefetching more important and historically Intel has always had a better algorithm.
Also, I'm not sure how far back you're going, when you say Intel is historically better at branch prediction. That was one of the areas of Zen 1 which saw the greatest amount of improvement. Overall, I don't have a sense of how big a gap exists between Zen 4 and Golden Cove, but the sense I get is that they're at least in roughly the same ballpark. Here are the two comparative plots in Chips & Cheese' analysis which give that impression:


You mean like the amount of assets, which range well into the hundreds of GB? Whether you have 32 or 96 MB of L3 cache would not seem to make a dent in that. Furthermore, if the game assets are the main bottleneck, that seems like data with a low reuse rate, as the GPU is really what's interested in those. Where L3 differences should have the greatest impact is in the realm of thread-to-thread communication, by avoiding the data needing to do a round-trip through DRAM and with things like collision detection, which do MxN interactions.Since todays games have such large datasets,
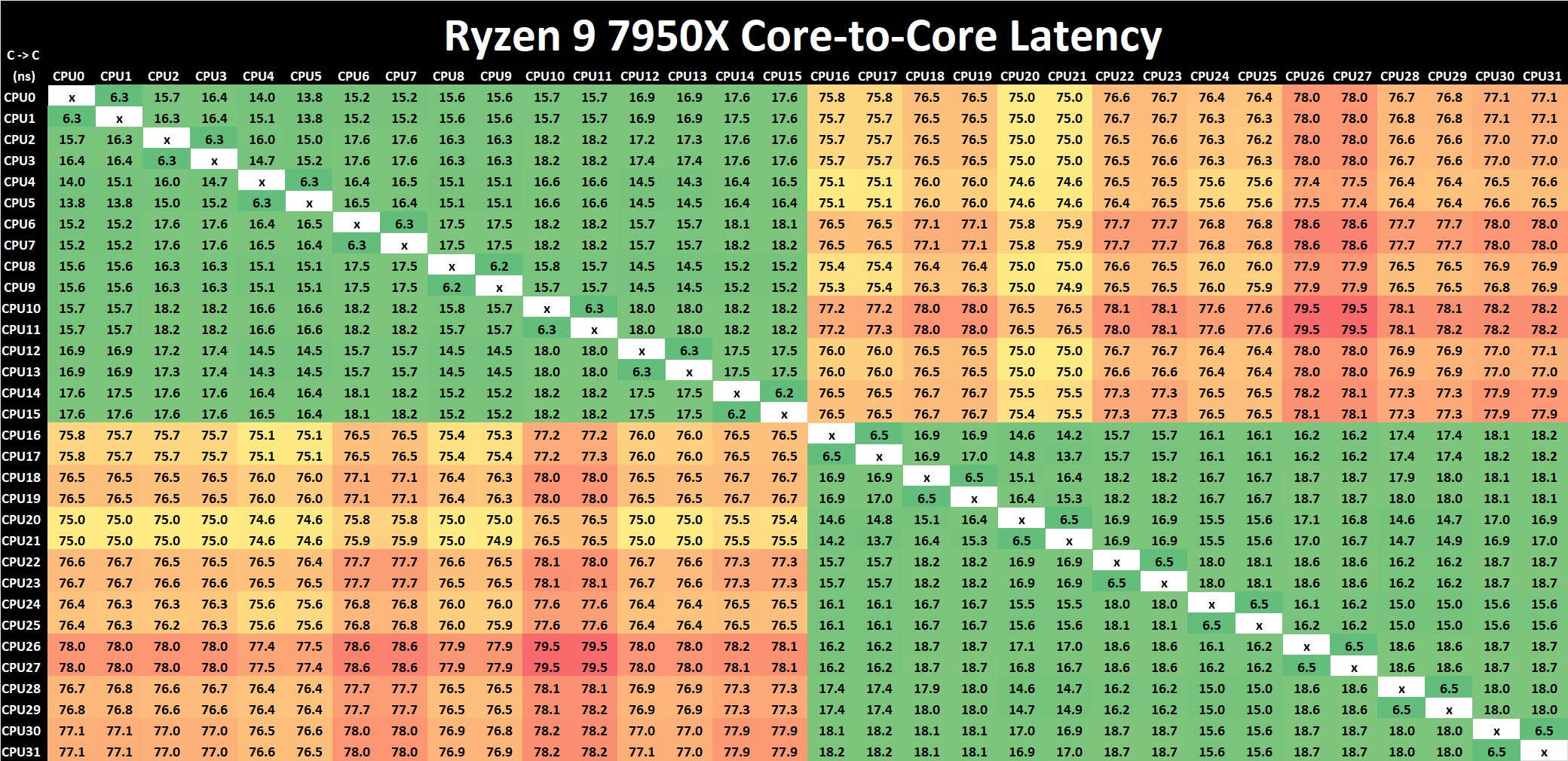
To get a sense of just how much better it is to keep thread-to-thread communication in L3 cache, consider the 7950X line in this plot of aggregate bandwidth, where a dataset of 64 MiB (remember, this is two regular CCDs, which each have 32 MiB) sees about 1.4 TB/s of bandwidth, but once you go above that, you hit DRAM speeds of like 1/20th that speed.

The wrong CCD has a 2-fold issue, for CPUs like the 7900X3D and 7950X3D. Not only don't those threads gain the benefits of more L3, but they also have a slower communication path to the cores on the other CCD. This shows the the penalty for going between CCDs.AMD's just brute forced it by making a large L3 cache and then cramming as much as possible. That is why those X3D CPUs perform so damn well in games but need special attention to prevent games running on the wrong CCD.
BTW, Chips & Cheese actually did an analysis of the 7950X3D, which included a couple of games:

AMD’s 7950X3D: Zen 4 Gets VCache
Compute performance has been held back by memory performance for decades, with DRAM performance falling even further behind with every year.
 chipsandcheese.com
chipsandcheese.com
They also went on to do some detailed analysis of gaming workloads on Zen 4. Here are a few interesting tidbits:
"Both gaming workloads are overwhelmingly frontend bound. They’re significantly backend bound as well, and lose further throughput from bad speculation. Useful work occupies a relatively minor proportion of available pipeline slots, explaining the low IPC."
"AMD has invested heavily in making a very capable branch predictor. It does achieve very high accuracy, but we still see 4-5 mispredicts per 1000 instructions. That results in 13-15% of core throughput getting lost due to going down the wrong path. Again, we have a problem because these games simply have a ton of branches. Even with over 97% accuracy, you’re going to run into mispredicts fairly often if there’s a branch every four to five instructions."
"Memory loads are the biggest culprit (for backend stalls). Adding more execution units or improving instruction execution latency wouldn’t do much, because the problem is feeding those execution units in the first place. Out of order execution can hide memory latency to some extent by moving ahead of a stalled instruction. ... AMD could address this by adding more entries to that scheduling queue. But as we all know, coping with latency is just one way to go about things. Better caching means you don’t have to cope as hard"
"Zen 4’s backend is primarily memory bound in both games. That brings up the question of whether it’s latency or bandwidth bound. ... Zen 4 is often waiting for data from L2, L3, or memory, but rarely had more than four such outstanding requests ... indicating that bandwidth isn’t an issue."
"Zen 4’s improvements over Zen 3 are concentrated in the right areas. The larger ROB and supporting structures help absorb memory latency. Tracking more branches at faster BTB levels helps the frontend deal with giant instruction footprints, as does the larger L2 cache. But AMD still has room to improve. A 12K entry BTB like the one in Golden Cove could improve frontend instruction delivery. Branch predictor accuracy can always get better. The store queue’s size has not kept pace and sometimes limits effective reordering capacity."

Hot Chips 2023: Characterizing Gaming Workloads on Zen 4
AMD didn’t present a lot of new info about the Zen 4 core at their Hot Chips 2023 presentation.
chipsandcheese.com
So, it sounds like you're right to focus on branch prediction as an issue, for games. Unfortunately, in spite of using a 7950X3D for the article, I see virtually no comparative between the different CCDs, looking at where the 3D cache is having the greatest impact. For that, it seems the best we've got is the prior article, which offers only this one tidbit:

"VCache makes Zen 4 less backend-bound, which makes sense because the execution units can be better fed with a higher cache hitrate. However, the core suffers heavily from frontend bottlenecks. VCache seems to have little effect on frontend performance, suggesting that most of the L3 hitrate gain came from catching more data-side misses."
It's just one game, but that suggests the benefit of 3D VCache isn't primarily to compensate for any weakness in branch prediction.
Last edited:
- Jan 20, 2010
- 20,147
- 11,133
- 79,540
FWIW, they certainly didn't plan to use 3D V-cache as a brute-force substitute for microarchitecture improvements. According to this, 3D V-cache was originally planned only to be used in EPYC server CPUs. The desktop X3D products arose as an "accident", when someone decided to put one in a desktop package and see how well games ran on it!AMD's just brute forced it by making a large L3 cache and then cramming as much as possible.
"the desktop implementation of AMD’s 3D-VCache technology started as an accident. The original implementation was designed for servers only, with AMD originally only testing 3D-VCache iterations of its EPYC server CPUs.
The reason AMD opted to research 3D-Vcache functionality on Ryzen in the first place, was due to an 'accident' during the production of presumably prototype Epyc 3D-VCache chips where 7 CCDs were left over in a batch that couldn’t be utilized in an EPYC chip — since EPYC CPUs required 8 CCDs at the time.
This led Mehra and his cohorts to re-purpose the seven V-Cache-equipped dies for desktop use, building out multiple designs including 8, 12, and 16 core variants. This is what lead AMD to research the capabilities of 3D-VCache in desktop workloads and discover the incredible gaming performance V-Cache offers, giving birth to the Ryzen 7 5800X3D."
https://www.tomshardware.com/news/amd-shows-original-5950x3d-v-cache-prototype
thestryker
Judicious
- Apr 19, 2016
- 5,889
- 4,068
- 36,690

I think maybe the implication was the amount of calculations going on effectively in the background. On one of the videos put up by L1T they talked about using Factorio for showing the benefits of extra cache and how at the lighter end the entire map's worth of compilation could be held in cache on X3D but if you went further in it would be too big and you'd see the real performance. What I find most interesting is that the cache is seemingly always enough of a benefit to offset the clock loss whether it provides and advantage or not.You mean like the amount of assets, which range well into the hundreds of GB? Whether you have 32 or 96 MB of L3 cache would not seem to make a dent in that. Furthermore, if the game assets are the main bottleneck, that seems like data with a low reuse rate, as the GPU is really what's interested in those. Where L3 differences should have the greatest impact is in the realm of thread-to-thread communication, by avoiding the data needing to do a round-trip through DRAM and with things like collision detection, which do MxN interactions.
systemBuilder_49
Distinguished
- Dec 9, 2010
- 144
- 52
- 18,670
Hardware Unboxed is staffed by a bunch of histrionic whiners. So is it no wonder that they make sensationally WRONG videos and title them with attention-seeking pictures that have NOTHING TO DO WITH REALITY? I banned them from my YouTube video feed 2 years ago, when they completely trashed the 7900xt for being the cheapest truly-4K video card and doing NOTHING WRONG, AND YOU SHOULD TOO !!Interesting. I would be interested to understand how your results are so much different than say, hardware unboxed. Are the non-canned benchmark sections of the games that much different? This really is an interesting topic.
Even Hardware Unboxed was getting decent results for the 9700X with Win 11 24H2 in the video they posted today
They just gripe about the price, and call the 7700X the winner of the showdown between the 14700K and the 9700X.
That does seem reasonable - the 7700X is a lot less expensive and just about as fast as a 9700X if you use Expo memory profiles for both CPUs
They just gripe about the price, and call the 7700X the winner of the showdown between the 14700K and the 9700X.
That does seem reasonable - the 7700X is a lot less expensive and just about as fast as a 9700X if you use Expo memory profiles for both CPUs
stuff and nonesense
Honorable
- Mar 10, 2020
- 760
- 535
- 11,790
Seems that they have been milking the narrative of AMD 9000 series CPUs being bad. I see the new post titles they put up but pass the videos by. It isn’t journalism…Hardware Unboxed is staffed by a bunch of histrionic whiners. So is it no wonder that they make sensationally WRONG videos and title them with attention-seeking pictures that have NOTHING TO DO WITH REALITY? I banned them from my YouTube video feed 2 years ago, when they completely trashed the 7900xt for being the cheapest truly-4K video card and doing NOTHING WRONG, AND YOU SHOULD TOO !!
-Fran-
Glorious
- May 3, 2007
- 9,571
- 3,127
- 47,640




No. It's just people that doesn't understand what they do or even cares to pay attention to their testing.Seems that they have been milking the narrative of AMD 9000 series CPUs being bad. I see the new post titles they put up but pass the videos by. It isn’t journalism…
Imagine NASCAR enthusiasts saying a WRX or an EVO are terrible cars because they're not that fast on the donut or in a drag strip compared to a solid axle Mustang with less WHP.
HUB focuses on gaming and that is what they like testing. Almost laser focusing there and HUB-Steve has been very vocal he only speaks for that segment. Ry9K is just worse value than Ry7K and there's nothing AMD can do about it until Ry7K just runs out and price adjustments kick in.
Context matters, but people loves skimming over details and form a biased narrative. At times, I'm also guilty of that.
Regards.
D
Deleted member 2986452
Guest
Hardware Unboxed is staffed by a bunch of histrionic whiners. So is it no wonder that they make sensationally WRONG videos and title them with attention-seeking pictures that have NOTHING TO DO WITH REALITY? I banned them from my YouTube video feed 2 years ago, when they completely trashed the 7900xt for being the cheapest truly-4K video card and doing NOTHING WRONG, AND YOU SHOULD TOO !!
Seems that they have been milking the narrative of AMD 9000 series CPUs being bad. I see the new post titles they put up but pass the videos by. It isn’t journalism…
Yeah I dropped my sub a while back from HUB... and J2C. I've seen other channels like GN say the 9000 series isn't very good.
I dunno man... I went for it because the 7950X was $523 and the 9950X was $623. For $100 I went with Zen 5 and the added performance even if it is only 10-15%.
What's funny though is I just googled Cinebench R23 scores and found this: R23 scores
It shows a 9950X at 41k for multi-core. I ran the test the other night on my system and scored 43,323 in multicore. I'm at work or I'd post a screenshot.
Point being... the 9000 series isn't even close to being "bad."
stuff and nonesense
Honorable
- Mar 10, 2020
- 760
- 535
- 11,790
9900x, PBO on,It shows a 9950X at 41k for multi-core. I ran the test the other night on my system and scored 43,323 in multicore. I'm at work or I'd post a screenshot.
ppt1000, other 2 settings to 500..
curve optimiser to -25 all cores,
Corsair 6000 cl40, expo auto settings,
cpu max temp set to 85c in bios,
PBO asked for 200 MHz overclock…
CB23, 34016 MC….
D
Deleted member 2986452
Guest
9900x, PBO on,
ppt1000, other 2 settings to 500..
curve optimiser to -25 all cores,
Corsair 6000 cl40, expo auto settings,
cpu max temp set to 85c in bios,
PBO asked for 200 MHz overclock…
CB23, 34016 MC….
Like I said... far from "bad." Heck they are pretty darn good at gaming too... and I'd much rather have the extra productivity cores/performance over a few extra fps in some random game when I'm already capped 60 fps in 4K.
TRENDING THREADS
-

-
-

-
News Introducing the Tom’s Hardware Premium Beta: Exclusive content for members
- Started by Admin
- Replies: 43
-
-
Question Is there anyway to force gsync through integrated graphics?
- Started by nelska
- Replies: 1
-
Question Is there any way to connect this multi-adapter to a UHD disc drive?
- Started by Jay_34
- Replies: 4
Space.com is part of Future plc, an international media group and leading digital publisher. Visit our corporate site.
© Future Publishing Limited Quay House, The Ambury, Bath BA1 1UA. All rights reserved. England and Wales company registration number 2008885.
 Twitter
Twitter